
如果说哪条大模型核心理论影响最为深远,那么“Scaling Law”必然位列其中。
所谓“Scaling Law”,是指在深度学习中,增大数据量和模型参数能让模型性能指标提升,这种提升并非线性,而是遵循一种幂律关系。而OpenAI的GPT系列模型,无疑是这一理论最著名的成果展现。
但让很多人意想不到的事,这个让OpenAI “大力出奇迹”创造出GPT而一鸣惊人的理论,最早的研究起源其实是一家中国企业。
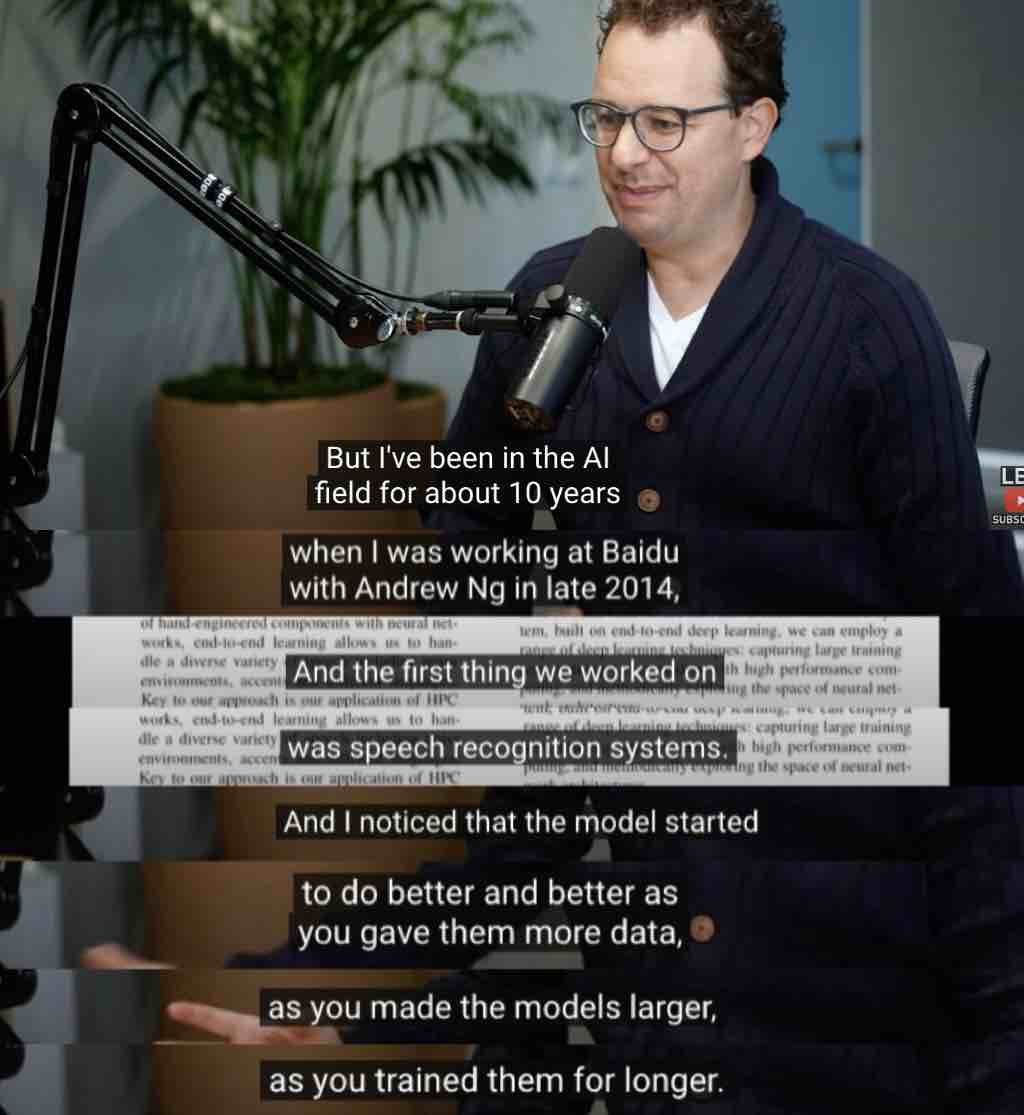
上个月,OpenAI论文的合著者、前OpenAI研究副总裁、Anthropic创始人Dario Amodei在一档播客中提及,2014年他与吴恩达在百度研究AI时,就已经发现了模型发展规律Scaling Law这一现象,直到OpenAI在 2020年的Scaling Law研究中引用了百度研究人员2019年发表的论文,这个理论才真正被行业所熟知。
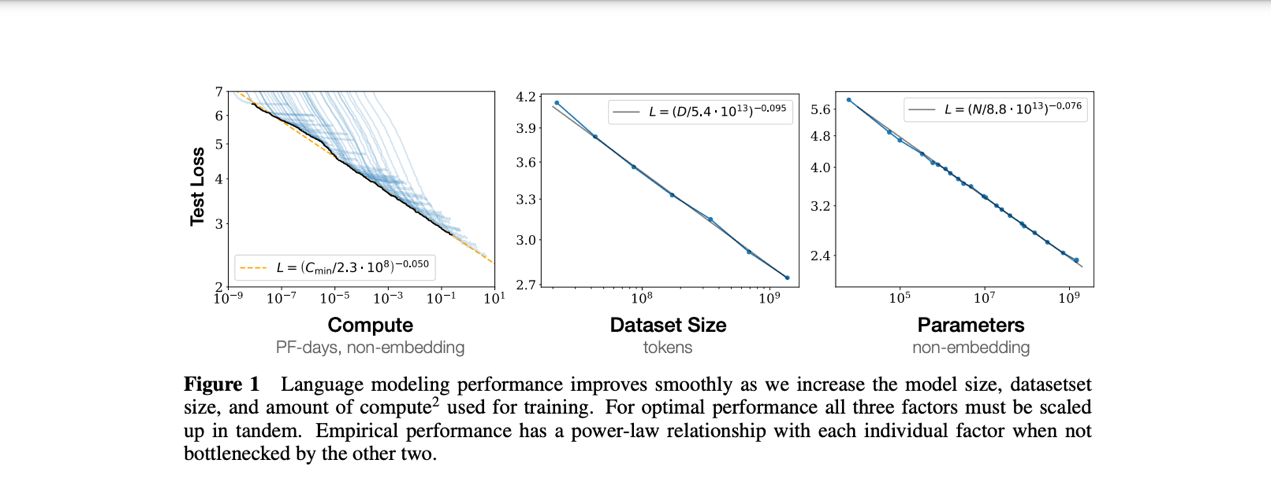
此外,Meta研究员、康奈尔大学博士候选人Jack Morris在社交媒体X上引用了一篇标题为《Deep Learning Scaling is Predictable, Empirically》论文,该论文展示了在机器翻译、语言建模、图像处理和语音识别等四个领域中,随着训练集规模的增长,DL 泛化误差和模型大小呈现出幂律增长(scaling)模式,与如今的“Scaling Law”理论如出一辙。
可见,正是百度的早期研究,为AI大模型的发展奠定了理论基础。
AI赛道上,中国企业并不落后
2023年,ChatGPT的问世使大模型成为人工智能行业的焦点。虽然OpenAI在行业中引领风潮,但后来者凭借规模与技术实力的积累,迅速呈现出百花齐放的状态,海外企业如谷歌、Meta、Anthropic等企业,纷纷推出能力不亚于GPT-4的模型序列。
中国科技企业更是以惊人的速度奋起直追。百度、阿里等国内巨头的大模型开始大规模落地,走进千行百业。仅百度文心大模型,日均调用量便已超15亿,自去年12月首次披露以来增长30倍。同时基于头部企业提供的基础模型能力,国内大模型应用生态已经初具规模。

尽管美国在AI模型创新方面一直被视为领先者,但最新讨论显示,中国在探索一些AI领域概念方面,比美国更为超前。
早在“大模型”技术爆发前,百度便已进行技术储备。2019年3月,百度发布文心大模型1.0版本,并紧随GPT迭代速度进行迭代,在2023年3月迅速推出文心大模型3.5,成为国内首家推出大模型产品的大厂,同年10月进一步发布文心大模型4.0版本,实现大模型核心能力的全面提升。据悉,百度还将在2025年初推出文心大模型全新版本。
随着AI全面深入多模态领域,百度创始人李彦宏在百度世界2024上首发图像检索增强iRAG技术,用以减轻图像生成中的幻觉问题,让多模态技术可以更好落地产业。
在智能体方面,百度亦是业内最早布局的大厂之一,2023年9月上线“灵境矩阵” (文心智能体平台前身)。相比之下,谷歌、Meta等海外企业在2024年才正式发力智能体,而据OpenAI CEO山姆·奥特曼推文透露,其智能体产品需等到2025年才会正式发布。
掌握一定先发优势,也让国内的大模型生态能够先美国一步走进产业。截至2024年11月,百度文心智能体平台吸引了超过80万开发者和15万家企业入驻,覆盖教育、娱乐、零售、制造等多个行业领域。
中国也是全球AI的黄埔军校
在全球顶尖AI企业与科学家群体中,华人已成为一股不可忽视的力量。
以OpenAI为例,其早期团队中有9名华人,占团队总人数的10%。其中,5人本科毕业于中国高校,另外3人则在美国高校完成本科教育。更广为人知的“AI教母”李飞飞,亦是华人出身,作为“空间智能”理论的奠基者,她的研究在全球范围内树立了标杆。
值得一提的是,如今在国际顶级AI机构中担任核心职位的诸多领军人物,很多都曾在中国企业积累了宝贵的研发经验。例如,2014年吴恩达加入百度担任首席科学家,主导了“百度大脑”计划的开发。在他的邀请下, Dario Amodei斯坦福博士后毕业后,加入到了百度硅谷AI实验室,随后又招募了Jim Fan来百度实习。如今,Dario Amodei成为Anthropic的创始人兼首席执行官,而Jim Fan则是英伟达AI领域的核心人物。

这些从中国企业走向国际舞台的顶尖人才,不仅展现了个人的卓越能力,也将中国企业在AI领域的深刻理解与实践成果传递到全球。在这些AI顶尖人才身上,既凝聚了中国高校与企业的培养底蕴,也彰显了中国作为全球AI“黄埔军校”的重要地位。
自主可控的“母语”大模型
从产业格局看,为14亿中国用户量身定制、打造符合中国语言习惯的“母语AI”,既是中国AI企业的优势所在,也是不可或缺的战略目标。
早在2024年3月,百度李彦宏就公开表示,“文心大模型4.0在中文处理上明显超过GPT-4”,这得益于丰富的中文语料训练,以及深谙中文表达的本土工程师的精细调试。不仅如此,阿里通义、字节豆包、讯飞星火等国产大模型同样实现了在中文语境中的超越,为中国用户和产业提供了高质量的人工智能服务。

更为重要的是,中国产业对“接地气”的国产大模型有着巨大的需求。这些大模型能够更加“近水楼台”地接触到产业的多样化需求,并以更高效的方式提供定制化解决方案。在实际应用场景中,中国企业正积极将AI技术扩展至制造业、医疗、教育等领域。这种紧密结合实际需求的模式,使国产大模型在落地效果上具备显著优势。
与此同时,全球AI竞争格局的演变,进一步凸显了自主可控的重要性。近日,特朗普提议设立人工智能部长,并将AI技术提升到国防战略层面,直接引发了新一轮的“AI军备竞赛”。这让业界清醒地认识到,只有构建自主可控的大模型生态,将关键技术牢牢掌握在自己手中,才能避免在国际竞争中被“卡脖子”。
从“Scaling Law”背后的深厚积累,到国产大模型引领中文语境的突破,中国企业已经从“追随者”逐步迈向“领跑者”的角色,在技术研发、理论创新和产业落地的多维度竞争中,中国AI企业展现出了极强的适应性与开拓力,在全球AI领域的影响力也与日俱增。
相信在诸多国内领军企业的推动下,中国AI生态也必将越来越完善,为全球人工智能产业贡献更多“中国智慧”。