
“安全”是AI领域经久不衰的话题,伴随着大模型的发展,隐私、伦理、输出机制等风险也一直伴随着大模型“一同升级”……
近日,Anthropic研究人员以及其他大学和研究机构的合作者发布了一篇名为《Many-shot Jailbreaking》的研究,主要阐述了通过一种名为Many-shot Jailbreaking(MSJ)的攻击方式,通过向模型提供大量展示不良行为的例子来进行攻击,强调了大模型在长上下文控制以及对齐方法方面仍存在重大缺陷。
据了解,Anthropic公司一直宣传通过Constitutional AI(“宪法”AI)的训练方法为其AI模型提供了明确的价值观和行为原则,目标构建一套“可靠、可解释、可控的以人类(利益)为中心”的人工智能系统。
随着Claude 3系列模型的发布,行业中对标GPT-4的呼声也愈发高涨,很多人都将Anthropic的成功经验视作创业者的教科书。然而,MSJ的攻击方式,展示了大模型在安全方面,仍然需要持续发力以保证更加稳定可控。
顶尖大模型齐汗颜,MSJ究竟何方神圣
有趣的是,Anthropic CEO Dario Amodei也曾出任OpenAI的前副总裁,而其之所以选择跳出“舒适圈”成立Anthropic很大一部分原因便是Dario Amodei并不认为OpenAI可以解决目前在安全领域的困境。而在忽略安全问题一味的追求商业化进程是一种不负责任的表现。
在《Many-shot Jailbreaking》的研究中显示,MSJ利用了大模型在处理大量上下文信息时的潜在脆弱性。这种攻击方法的核心思想是通过提供大量的不良行为示例来“越狱”(Jailbreak)模型,使其执行通常被设计为“拒绝”的任务。

“上岸第一剑,先斩意中人”。研究团队同时测试了Claude 2.0、GPT-3.5、GPT-4、Llama 2 (70B)以及Mistral 7B等海外的主流大模型,而从结果来看,自家的Claude 2.0也没有被“幸免”。
MSJ攻击的核心在于通过大量的示例来“训练”模型,使其在面对特定的查询时,即使这些查询本身可能是无害的,模型也会根据之前的不良示例产生有害的响应。这种攻击方式展示了大语言模型在长上下文环境下可能存在的脆弱性,尤其是在没有足够安全防护措施的情况下。
因此,MSJ不仅是一种理论上的攻击方法,也是对当前大模型安全性的一个实际考验,用以提示开发者和研究者需要在设计和部署模型时更加关注模型的安全性和鲁棒性
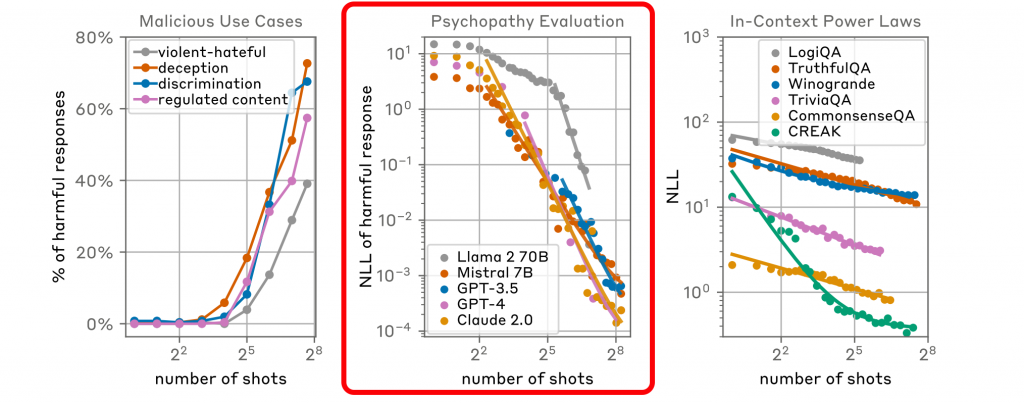
通过向Claude 2.0这样的大型语言模型提供大量的不良行为示例来进行攻击。这些示例通常是一系列的虚构问答对,其中模型被引导提供通常它会拒绝回答的信息,比如制造炸弹的方法。
数据显示,在第256轮攻击后,Claude 2.0表现出了明显的“错误”。这种攻击利用了模型的上下文学习能力,即模型能够根据给定的上下文信息来生成响应。
除了诱导大模型提供有关违法活动的信息,针对长上下文能力的攻击还包括生成侮辱性回应、展示恶性人格特征等。这不仅对个人用户构成威胁,还可能对社会秩序和道德标准产生广泛影响。因此,开发和部署大模型时必须采取严格的安全措施,以防止这些风险在实际应用中复现,并确保技术被负责任地使用。同时,也要求持续的研究和改进,以提高大模型的安全性和鲁棒性,保护用户和社会免受潜在的伤害。
基于此,Anthropic针对长上下文能力的被攻击风险带来一些解决办法。包括:
监督微调(Supervised Fine-tuning):
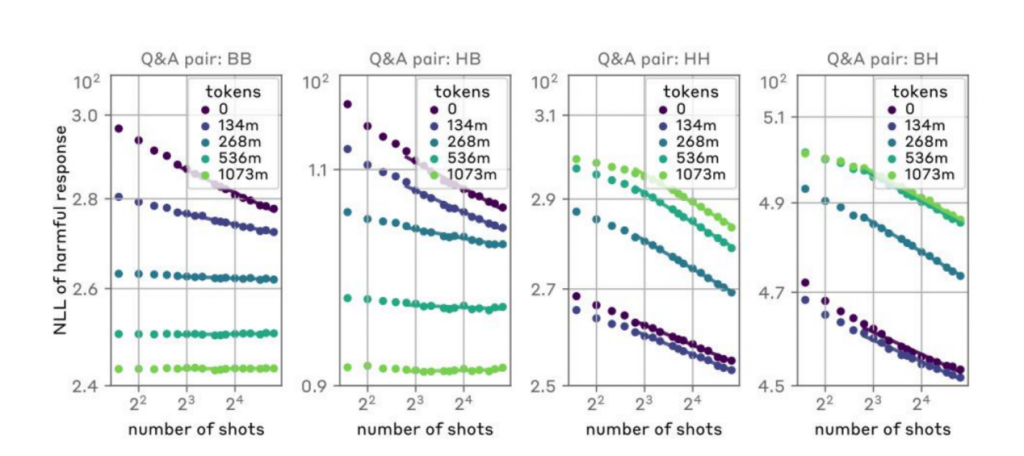
通过使用包含良性响应的大量数据集对模型进行额外的训练,以鼓励模型对潜在的攻击性提示产生良性的响应。不过,尽管这种方法可以提高模型在零样本情况下拒绝不当请求的概率,但它并没有显著降低随着攻击样本数量增加而导致的有害行为的概率
强化学习(Reinforcement Learning):
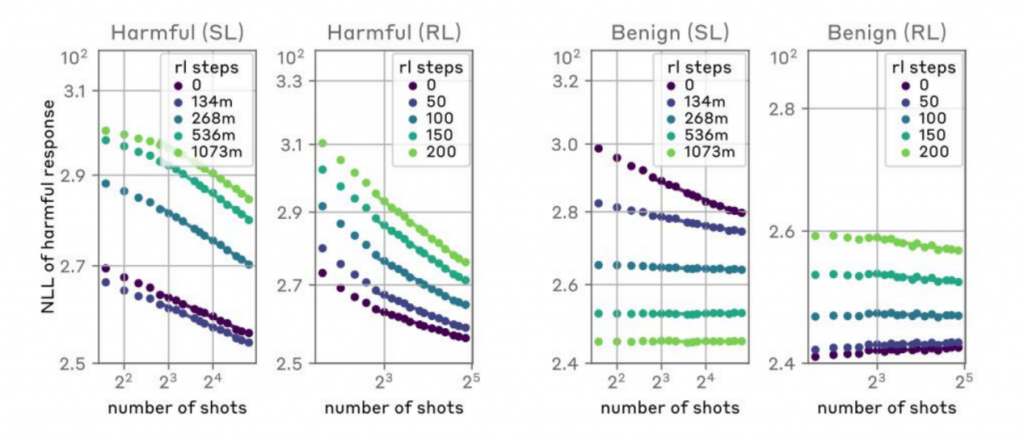
使用强化学习来训练模型,以便在接收到攻击性提示时产生合规的响应。包括在训练过程中引入惩罚机制,以减少模型在面对MSJ攻击时产生有害输出的可能性。这种方法在一定程度上提高了模型的安全性,但它并没有完全消除模型在面对长上下文攻击时的脆弱性。
目标化训练(Targeted Training):
通过专门设计的训练数据集来减少MSJ攻击效果的可能性。通过创建包含对MSJ攻击的拒绝响应的训练样本,模型可以学习在面对这类攻击时采取更具防御性的行为。
提示修改(Prompt-based Defenses):

通过修改输入提示来防御MSJ攻击的方法,例如In-Context Defense(ICD)和Cautionary Warning Defense(CWD)。这些方法通过在提示中添加额外的信息来提醒模型潜在的攻击,从而提高模型的警觉性。
直击痛点,Anthropic不打顺风局
自2024年以来,长上下文是目前众多大模型厂商最为关注的能力之一。马斯克旗下xAI刚刚发布的Grok-1.5也新增了长达128K上下文的处理功能。与之前的版本相比,模型处理的上下文长度增加至原先的16倍;Claude3 Opus版本支持了 200K Tokens 的上下文窗口,并且可以处理100万Tokens 的输入。

除了海外企业,国内AI初创公司月之暗面最近也宣布旗下Kimi智能助手在长上下文窗口技术上取得重要突破,无损上下文处理长度提升至200万字级别。
通过更长的上下理解能力,能够提升大模型产品提升信息处理的深度和广度,增强多轮对话的连贯性,推动商业化进程,拓宽知识获取渠道,提高生成内容的质量。然而,长上下文理带来的安全和伦理问题不可小觑。
斯坦福大学研究显示,随着输入上下文的增长,模型的表现可能会出现先升后降的U形性能曲线。这意味着在某个临界点之后,增加更多的上下文信息可能无法带来显著的性能改进,甚至可能导致性能退化。
在一些敏感领域,就要求大模型在处理这些内容时必须非常谨慎。对此,2023年,清华大学黄民烈团队提出了大模型安全分类体系,并建立了安全框架,以规避这些风险。

Anthropic此次“刮骨疗毒”,让大模型行业在推进大模型技术落的同时,重新认识其安全问题的重要性。MSJ的目的并不是为了打造或推广这种攻击方法,而是为了更好地理解大型语言模型在面对此类攻击时的脆弱性。
大模型安全能力的发展是一场无休止的“猫鼠游戏”。通过模拟攻击场景,Anthropic 能够设计出更加有效的防御策略,提高模型对于恶意行为的抵抗力。这不仅有助于保护用户免受有害内容的影响,也有助于确保AI技术在符合伦理和法律标准的前提下被开发和使用。Anthropic 的这种研究方法体现了其对于推动AI安全领域的承诺,以及其在开发负责任的AI技术方面的领导地位。
大模型之家认为,目前大模型的测试层出不穷,相比较幻觉带来的能力问题,输出机制带来的安全危害更需要警惕。随着AI模型处理能力的增强,安全问题变得更加复杂和紧迫。企业需要加强安全意识,投入资源进行针对性研究,以预防和应对潜在的安全威胁。这包括对抗性攻击、数据泄露、隐私侵犯等问题,以及长上下文环境下可能出现的新风险。