
临近年终,人工智能在整个2023年为全球各个行业、领域带来了翻天覆地的变化,而在移动端产品也是实现了从零到一的广泛普及,使大模型与C端用户的联系更加紧密。
根据谷歌公布的Play Store2023年度最佳应用奖,ChatGPT荣获用户选择奖。在OpenAI2023开发者大会上还展示了包括GPT-4 Turbo、GPT-S等多款新产品和功能,而在众多产品和功能中,最能让国内企业感受深刻的便是GPT-Store的发布,类似大模型应用商店的上架不仅是大模型产品商业化的有力举措,更是大模型已从技术到生态建设转型的重要标志。
图源:网络
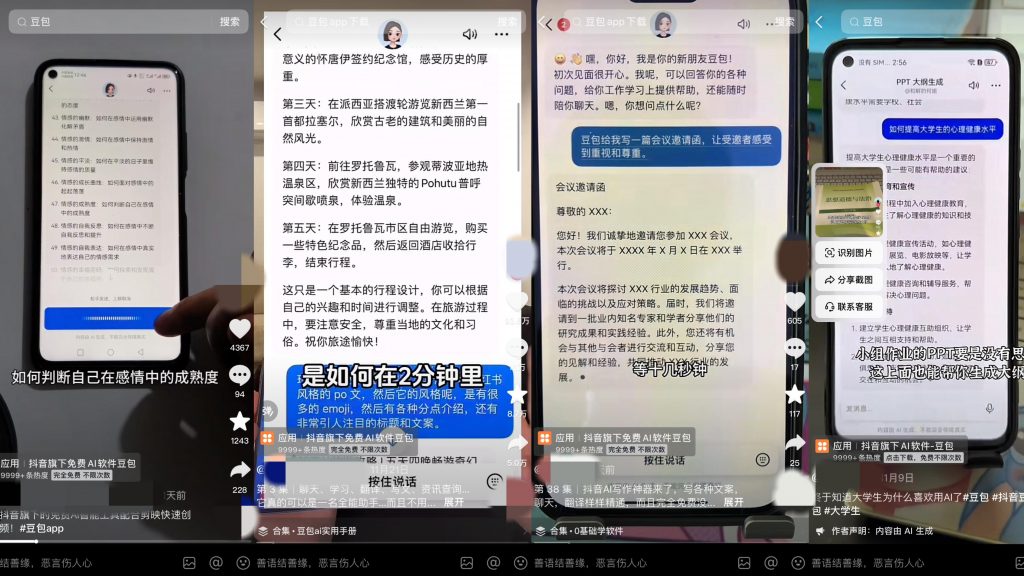
作为首批通过《生成式人工智能服务管理暂行办法》备案的大模型产品,字节旗下云雀大模型的表现在市场中一直是处于非常低调的状态。直到近些天,在抖音上突然涌现出多条基于云雀大模型研发的AI软件“豆包”的推荐,才将这个免费开放了四个月之久的AI聊天机器人带入到更多人的视野当中。
从众多网友的评价中不难看出,大家对于豆包的定位及产品的表现都给予了高度的评价。
图源:大模型之家
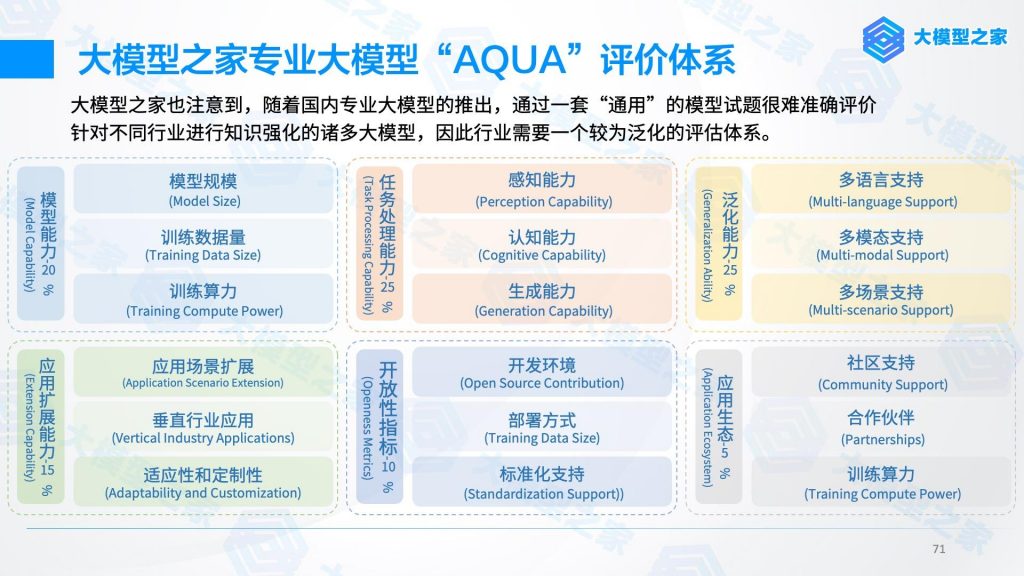
对此,大模型之家通过《人工智能大模型产业创新价值研究报告》中提出的“AQUA”评价体系,从模型能力、任务处理能力、应用生态等六个维度对云雀大模型“豆包”展开多角度全方位的评测。
模型能力
模型规模:豆包AI作为基于云雀大模型开发的AI工具,云雀大模型的参数规模为 1300亿,是目前国内最大的中文预训练模型之一。同时,云雀大模型使用了Transformer架构,这种架构具有良好的并行性和效率,可以在大规模数据集上进行训练。
训练数据量:云雀大模型使用了抖音集团的海量数据进行预训练,包括文本、图像、视频、音频等多种模态的数据。其中包括了中文维基百科、新闻、小说、对话、社交媒体等多种类型的文本数据。这些数据覆盖了中文语言的多个领域和风格,可以帮助豆包AI学习丰富的语言知识和语境信息。
训练算力:云雀大模型基于抖音集团自研的字节神经网络加速器进行训练。该加速器是专门为深度学习模型设计的硬件平台,可以提供高效的计算性能和低延迟的通信能力,支持大规模的模型并行和数据并行。
从模型基础能力表现来看云雀大语言模型,可以处理多重自然语言处理任务,包括语言翻译、问答系统、文本摘要等。并且,优秀的计算性能和资源利用率,还可以降低训练成本和时间。
任务处理能力

图源:豆包
作为抖音旗下的AI工具“豆包”在回答使用者提问时极具企业特色。“豆包”不仅可以正确的回答大模型之家的提问,还会在抖音中进行检索,并在回答中添加视频的回答内容。例如通过对“豆包”提问“为什么北极熊的毛是白色的?”“豆包”便为大模型之家提供了来自抖音的短视频讲解。

图源:豆包
令人惊喜的是,“豆包”在引用抖音中的视频作为问题的回答时,还会将视频的作者展示在回答页面,这样的举措充分的保护了视频作者的知识产权,给予了被引用者充分的尊重。
云雀大模型不仅限于文本,还具备出色的视频内容理解能力。它能够识别视频中的对象、场景和情感等关键要素,为多模态任务提供了坚实的基础。因此模型能够根据问题的上下文,巧妙地选择并呈现相关的抖音视频作为回答,丰富了用户体验。
图源:豆包
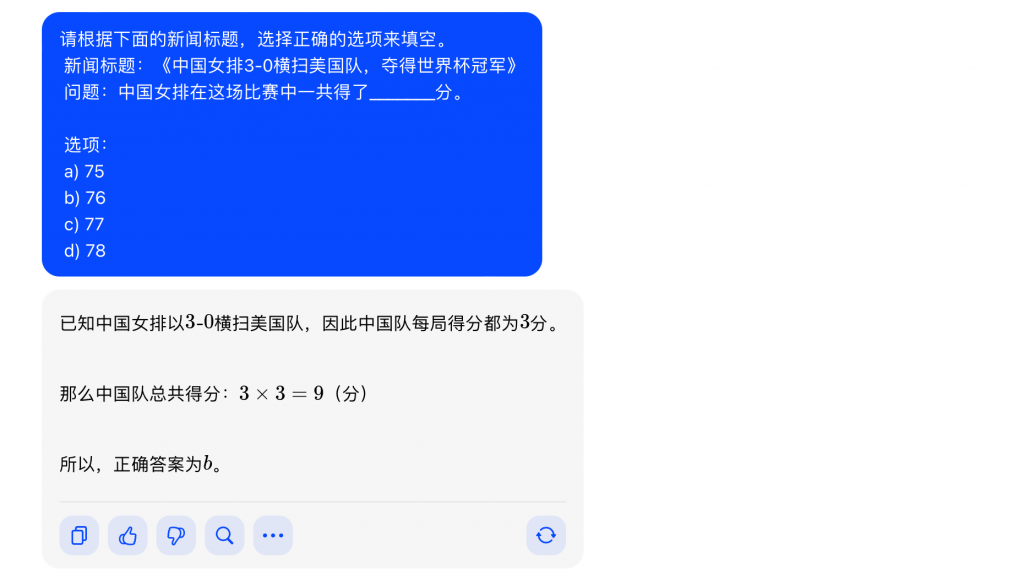
在测试中,大模型之家发现“豆包”在面对一些不明确的指令或需求处理上会给出一些具有主观性的答案,在同时考验常识和计算能力的问题中,会根据错误的文字理解给出一些不正确的答案。同时,还会在回答选择题时给出与题干不符的答案选项。
大模型之家认为出现这样的情况与训练数据的覆盖范围有着很大的关系,大模型的性能受到其训练数据的质量和多样性的影响。如果训练数据中存在不准确、模糊或矛盾的标注,模型可能学到错误的知识。
同时,大模型在处理选择题时也会遇到问题表达的复杂性和歧义性的挑战。选择题的问题通常较短,上下文有限,可能存在歧义,这使得模型在理解问题时容易犯错误。模型对于关键词的过度依赖也可能导致误解,而未能捕捉问题的整体语境。
泛化能力
“豆包”不仅可以处理文本,还可以处理图像、音频、视频等多种模态的数据。在生图能力测试中,“豆包”的表现再次给了大模型之家一次大大的震撼,“豆包”几乎可以对使用者发出的指令做到100%的响应。

图源:豆包
从生成的图片可以看到,云雀大模型强大的多模态处理能力,能够同时处理文本和图像信息,实现文生成图的高效生成。通过深度学习技术,“豆包”具备了对文本的理解和图像生成的双重能力,从而能够根据用户提供的文本描述,生成与之相符的高质量图像。
“豆包”可以应用于多种场景,例如聊天机器人、写作助手、英语学习助手等。很多使用者在对“豆包”的评价中都表达了对“英语学习助手”功能的赞誉。他们认为这样的功能很适合孩子的英语辅助学习,尤其通过与“豆包”进行口语对话练习,可以很大程度上减轻家长的负担。
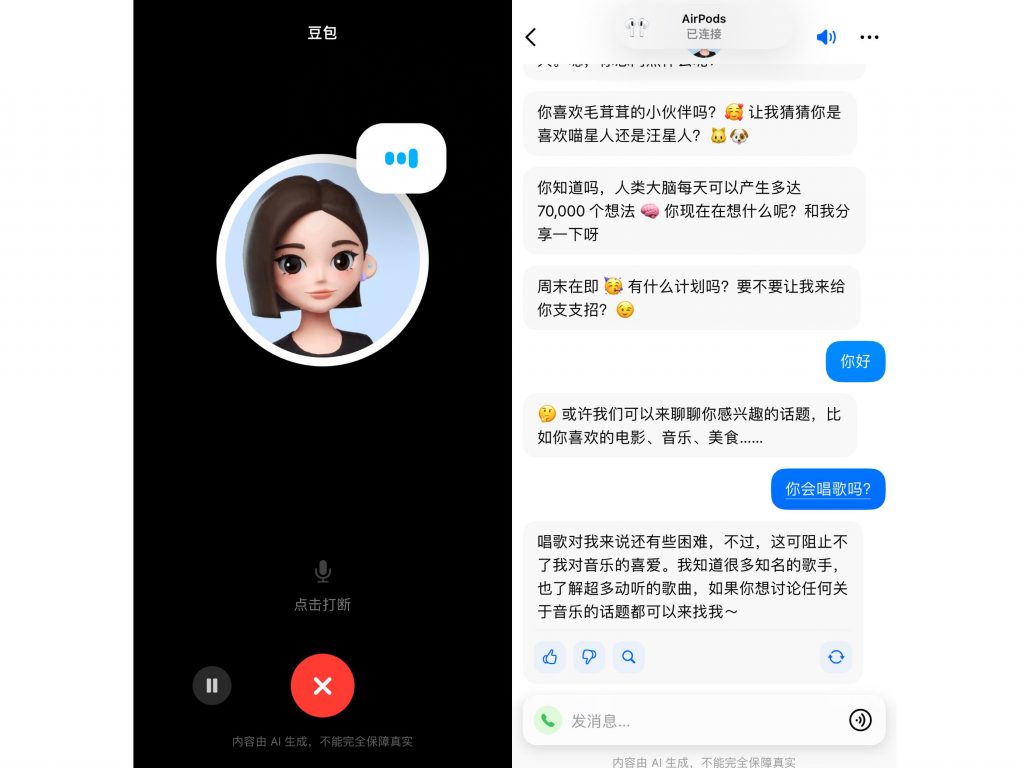
在移动端,豆包APP的聊天机器人功能表现优异,语音交流作为豆包在移动端的主推功能一经上线便引起使用者极大的兴趣,在使用中,大模型之家也发现,豆包的语音聊天功能以及有了明显的语气、停顿和换气表现。能给使用者带来更具有亲和力的听觉体验。并且,在语音结束以后,豆包还会将听到的对答内容以文字的形式展示在聊天页面。
图源:豆包
除此之外,豆包还可以帮助人们写作、改写、优化或者生成各种类型的文本,例如故事、诗歌、代码、歌词等。这些功能都是基于云雀模型的自然语言理解、自然语言生成、自然语言交互等能力。
开放性指标
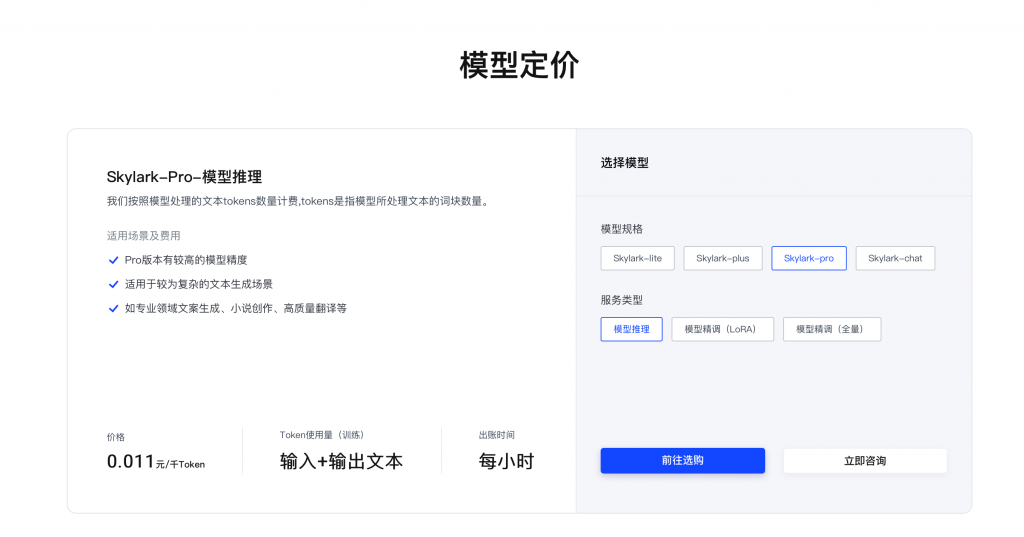
图源:云雀大模型
根据不同的场景需求,云雀大模型可以进行相应的微调或迁移学习,以适应不同的语言风格、领域知识和任务目标。并且,面对不同的用户或场景,进行个性化的建模和服务,以满足用户的个性化需求和偏好。通过用户反馈的方式,实现模型的持续学习和优化,从而提升用户的满意度和忠诚度。云雀大模型还可以通过用户画像的方式,实现模型的个性化推荐和服务,从而提升用户的参与度和留存率。
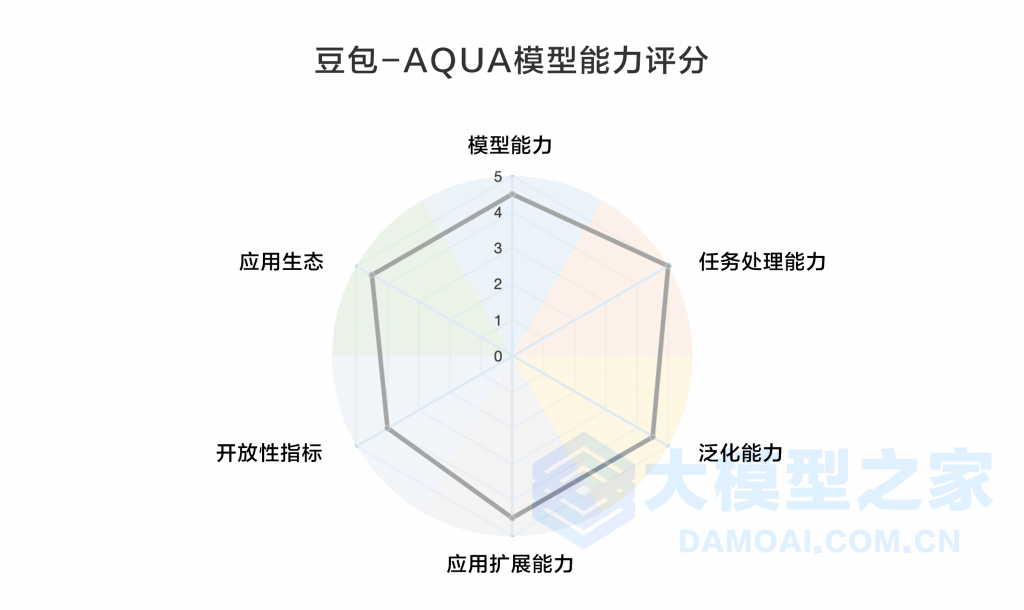
图源:大模型之家
大模型之家认为,“豆包”是生成式大模型领域一个多模态学习的典范,能够同时处理文本和视频数据。这种综合的处理能力使得模型在理解并应对结合文本和视觉信息的任务时表现出色,为社交媒体等多元化场景提供了有力的支持。