在RTE2023第九届实时互联网大会上,声网首席科学家、CTO钟声带来了《AI时代 实时互动何去何从》的主题演讲。如今,AIGC的浪潮已经开始席卷各行各业。在机遇与挑战背后,到底什么才是AI时代真正的解法?
关于这一点,钟声指出,未来,我们除了要做负责任的AI之外,在端上和边缘上的分布式实时智能将成为价值公平分配的重要技术手段,也是减缓中心化AGI对人类威胁的有效途径,这也注定会成为一个新的技术发展趋势。

本文内容基于演讲内容进行整理,为方便阅读略有删改。
万事都将归于一统,由AGI接管
今天,我主要从拉长时间和缩短时间两个维度分享我的思考。五年前,我在第四届RTE大会上分享过,当视频遇到互联网时,社交媒体、游戏、金融、医疗、教育、IoT等领域都会发生变化, 内容丰富且多样化。
在手机为入口的时代,一切都将变得不可预测,碎片化、随时随地可消费的内容会变得更有个性和场景化,对沉浸式体验也提出更多的要求。当时我们就提出,有趣精彩的内容需要被更有效的发现,Touch(触摸)为主的交互手段还不够,需要变得更有力,需要增加通过语音、手势、眼神甚至是脑机接口去互动。
如此前预测所言,抖音和TikTok后来成功利用算法推荐把有趣精彩的内容展示给大家,互动的方式也出现了STT、TTS以及脑机接口这样的形态,在虚拟现实或沉浸式体验方面,苹果也发布了Vision Pro,还能通过眼神和手势交互。
把时间拉回到十几万年以前,人类过去发展长河里的绝大部分历史都只能靠口口相传,受限于物理介质的限制,内容的表达方式成了一个瓶颈。
直到印刷技术的出现,一些经典的知识能够以纸质书本的方式被表达出来,传递到千家万户,使知识和智慧得以扩散,促进社会进步。但书本形式的内容分发仍然是一个瓶颈。
最近二三十年,互联网的出现几乎零成本的解决了内容的分发问题。PGC内容通过数字媒体的方式进行表达,从内容消费的角度上,感兴趣的内容何以被发现,催生了搜索引擎,Google就是这里面最典型的一个代表。
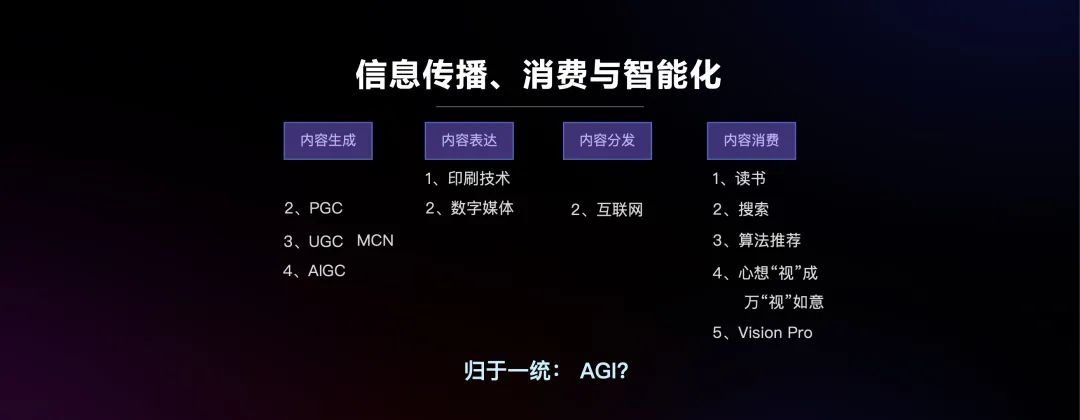
再往后就出现了UGC,大量web2.0用户产生自己的内容,这时发现感兴趣的内容就更难了,内容消费端出现了推荐算法技术。这时,内容生成也逐渐成为成本最高的环节,较高成本地运营 MCN成了趋势。
而近期AIGC技术的出现和进步将可以克服精品内容稀缺的瓶颈。那么,大量精品内容未来将以怎样的方式被体验和消费呢?我们认为,随着实时互动技术的发展,在消费端几乎可以做到心想“视”成、万“视”如意,AIGC将生成符合我们意愿的内容,消费方式也出现了像Vision Pro这样带来沉浸式现场感的产品。从信息传播消费和智能化的趋势可见,未来似乎万事都将归于一统,由AGI接管。
大模型带来的新问题
从2017年的Transformer出现,到如今的ChatGPT-4,不可否认,过去五年里最典型的事件就是大模型的突破。Transformer主要是解决了关注重点、广泛关联的问题;ChatGPT-3等大模型则通过海量的互联网数据投喂、将数据进行了沉淀,并通过用户反馈数据训练及PPO近邻策略优化,取得了类似人的智力。GPT-4的参数量进一步增加到1万亿以上,据说GPT-5更将是一个100万亿参数级别的超大模型。
人工智能的发展,让信息传播和消费智能化的趋势越来越明显,万事归于中心化AGI接管的趋势和威胁也越来越明显。大模型在带来发展机遇的同时,也带来了计算需求快速增长、算力受能源供给力限制、大模型数据资源不够、存储需求增长过快等问题。
首先是计算需求的快速增长。2021年,SOTA LLMs (GPT3) 训练需要约5000张GPU卡,到了2022、2023年,SOTA LLMs(GPT4,1T参数量),就需要大于10000张 A100 GPU卡。如果GPT5的参数量达到100T,那就意味着训练需要约50000张H100 GPU卡。这样的计算需求,几乎只有极少数的大公司才负担得起。
另一个问题是算力受能源供给力限制。2021年,芯片行业一个相关的报告指出,预测到2030年左右,能源供应会供不应求,价格也会极速上升,不可能再提供足够的算力给日益增长的计算需求,能源价格会相应上升并制约计算需求。
此外,大模型还将面临数据资源不够的局面。到2026年,可供训练AI高质量的公共数据将很缺乏,人与人、人与机器人的互动产生的数据将无法用以进一步提升AI能力来解决未知的问题。
存储需求增长过快也是一个问题,目前来看,存储的供需差异也非常大。安全方面,由于AI是朝着通用人工智能和超级人工智能方向发展的,未来也将存在很大的威胁到人类命运的可能。正如“Humans are hooked. Machines are learning”那张漫画所表达的一样,人类被钩住了,机器在借机学习进步。
分布式、实时智能将成为解法
过去,科学革命、工业革命,尤其是印刷技术的进步把新的知识、智慧之光通过书本的形式传递给更多人,最终爆发了宗教革命、打破中世纪天主教对人们的桎梏,并产生了人类社会以人为本的新文明形式和意识形态,这是知识智能传播开来起到的一个很好作用。
信息传播经历了十几万年的变化,才走到今天。未来AGI会不会成为新的高人一等的“上帝”,让我们沦为二级公民,最重要的仍然是智能传播能否更广、能否让更多人享受智慧。我认为,未来除了要做负责任的AI之外,在端上和边缘上的分布式实时智能将成为价值公平分配的重要技术手段,也是减缓中心化AGI对人类威胁的有效途径,这也注定会成为一个新的技术发展趋势。
从技术上讲,我们要做分布式、实时智能,让端和边缘智能的计算、能耗、数据需求更合理,带来实时和低成本。另外,要通过分布式实时智能做好隐私保护以及个性化 AI。这方面我们需要有更多新型算法和芯片架构:高效端/边 AI算法和计算芯片,高效的算法甚至能降低100万倍的复杂度。

另外是开源,开源最重要的是可以把对应的能力和智慧传播给更多人,让更多人参与共建。Facebook做得很好,他们在LLAMA2和LLAMA2 Long上已经取得了很好的效果,70B算法在很多方面已经超过ChatGPT-3.5。去中心化技术和底层芯片架构也很重要,目前高通这样的一些公司也在致力于在移动端上实时运行大语言模型。
我认为,AGI将走进实时互动,实现人人可分身,帮助在应用场景中复制名师、朋友、网红,甚至普通人也将通过AI分身丰富体验、缓解时间稀缺的终极瓶颈。普通人可以让分身去参与世界上很多同时发生的有趣的事,再让分身回来给我讲发生了什么精彩故事,这都将是非常美好的事,是对人们生命体验的提升。
从技术的角度简单总结,可以是语音转文字、文字再通过ChatGPT产生对话文字、文字再转成语音,最后用语音驱动写实的形象,来实现分身。语音、文字可以是真人产生的,也可以是机器产生的,最终可能出现,在人机AI混合世界里不分你我的阶段。
实时AI分身的三个实时写实
实时AI分身需要三个实时“写实”能力:实时写实对话、实时写实声音、实时写实形象。和大家简单介绍一下,这几方面的研究情况,实时运行的实现离不开芯片的支持,也离不开算法上的探索。相关信息显示,高通准备在明年支持像LLAMA2这样的开源模型(实际上这种能力的芯片已经出来)。
在算法上也有很多研究,在《Textbooks Are All You Need II》文章中,介绍了数据量只有1.3B、微软做的Phi-1.5,它是一个基于transformer,拥有24 layers和32 heads的架构,训练数据也小一个数量级,用30B和100B的tokens。
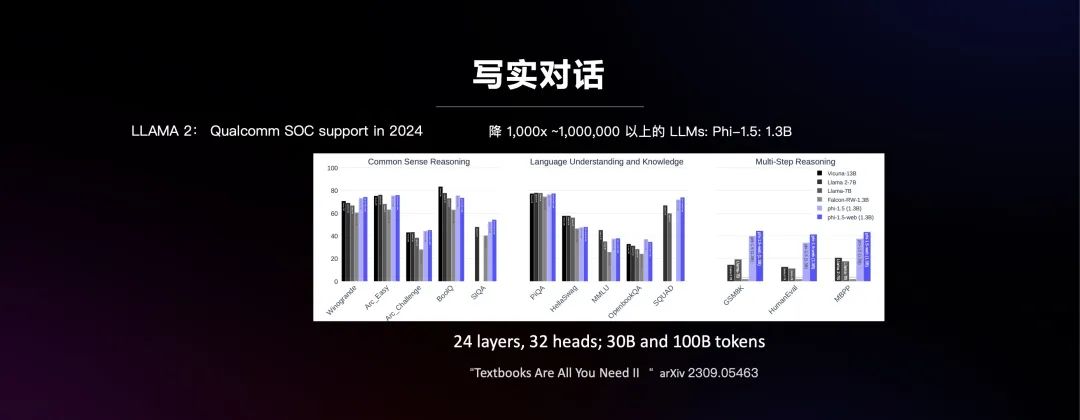
这篇文章的主要结论是,如果都用教科书上的内容去训练,肯定会产生比较好的效果,但如果用互联网上的内容去训练,效果未必是好的。最好的结果是把精心挑选的、教科书式的内容与web内容结合在一起。大部分情况下,它都比大十倍的13B模型都要好,不如13B模型的地方也相差无几的。所以,稍小一点的模型特别有希望,关键是要找到好的数据和训练方法。
训练方法也是有讲究的,刚提到的LLAMA2、LLAMA2 Long有一些很有趣的结论,比如用长的上下文数据会带来更优秀的结果,后续可以逐步的加上长期训练,且不需要从头就开始耗时耗算力的用最长的数据去训练,这些都为实时低延时方向提供了更多的希望。
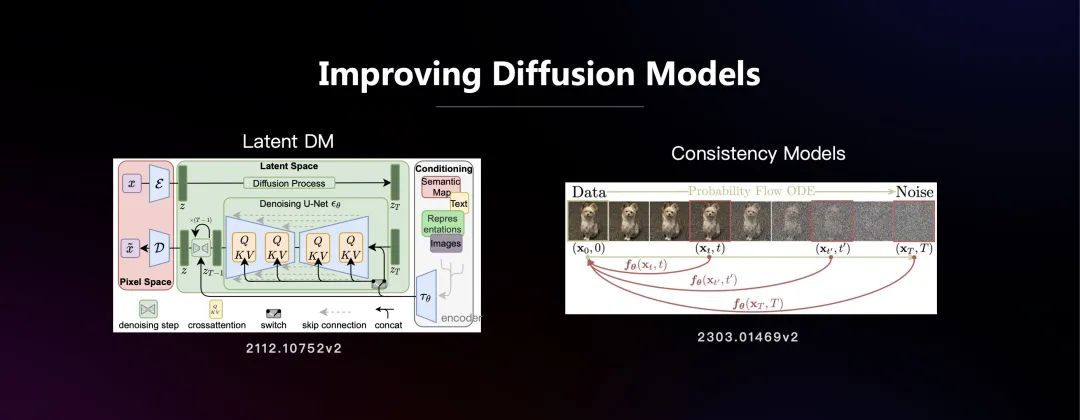
在写实形象这一块,简单介绍一下扩散模型。扩散模型的原理很简单,和我们理解的扩散道理很像,比较集中的分子会逐渐扩散到随机的分子,并均匀分布,最终混乱。扩散模型的腐化过程通常要分成几千步微小的腐化,每一步都是近似可逆向的过程,这样推理时间就很长,更别说训练了。
为了把模型缩小,变得更实时、时间更短,也有一些研究在进行。比如引入一个隐空间,在隐空间里做腐化,并在缩小的隐空间里做逆向的恢复。同时,为了把文本提示和恢复的过程联系在一起,又引入了一个Encoder,这个Encoder可以把文本转换成一个可以做互相关联的Q-K-V值,再利用transformer机制。通过这样的训练,就能把文本的语义和实际生成的图像关联起来,在最终做推理的时候,就可以从一个文本和一个随机的向量恢复出想要的图像。
这样带来两个好处,一是在latent Space上,算力往往会小很多,另一方面是可以把语义关联起来用文生图,这个逆过程仍然需要很多步。另外一个方向是consistency models,如果能让腐化过程中每一步都能从任何一个点回到原始那个点,就不需要一步一步逐渐恢复清晰的图,可以一步到位,这会极大地降低算力的要求。
再者是三维重构,人脸可以通过多幅⼈脸正交基线性加权得来。用人脸大数据级,通过PCA主成份进行分析,提出正交基,当一个新人脸进来的时候就能找到正交基里相应的系数,再一组合,就出现了新人的三维模型重建。再有就是神经辐射场技术NeRF,我去年的RTE大会上讲过,也是进来流行的三维重构的重要方法,这里因时间关系不再细讲。
写实声音现在最大的挑战是要有一个模型能够很泛化,训练完以后,任何人都能模拟出他的声音、韵律和风格。这方面微软最近发表了Neural speech 2 (NS2),用扩散模型来预测编码域中的变量。通常情况下,编解码器是把一段输入的语音作为输入进行压缩,再恢复成原始声音。NS2将文本通过diffusion model预测出压缩域里对应语音的Latent 变量z,再用decoder直接把z恢复成语音信号。这种方式可以用TTS文本生成语音。
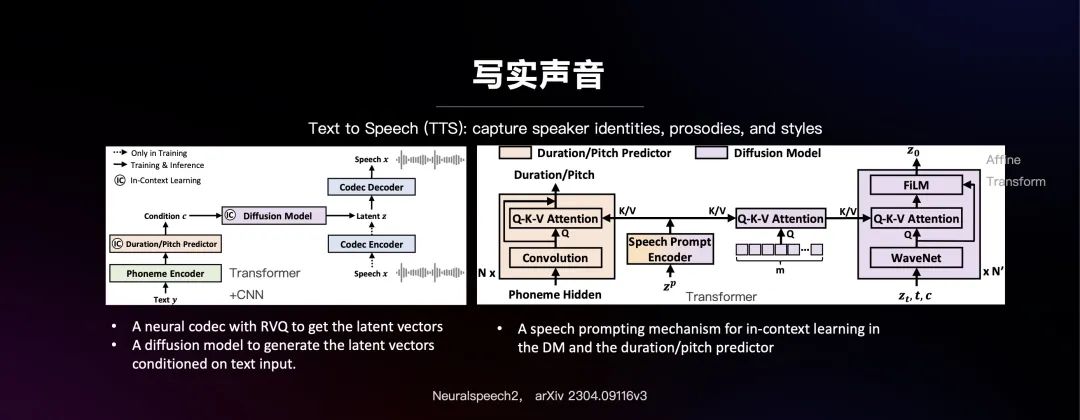
扩散模型里还有一些细节,为了把文本和语音连起来,会在训练的时候引入一层注意力机制,把文本经过Phoneme(音素)编码器产生的Phoneme Hidden与实际的语音做transformer关联,再将关联的结果作为一个条件输出到解码器这边做注意力关联,最后通过一个仿射变换生成拟真的声音。这个是今年上半年的一个研究结果,利用训练好的推理模型,用任何一个人的一小段声音都能立刻将更多的·文字生成听似一样的声纹、韵律和风格。
从信息传播到消费与实时分布式智能的角度回顾一下,我们可以看到AI为什么走到今天这一步是很合逻辑的,再往下发展会是什么样的方式呢?在内容消费上,未来实时超高清的内容会越来越多,并且需要实时传输。再加上人人都需要AI分身的趋势洞察,未来要传输的内容一定会出现指数型的递增,进而也会要求通信基础设施需要有很大的提升。我的一个预测是,具备端边实时智能的⾼清实时互动能⼒将成新趋势和竞争焦点。要想缓解AGI带来的威胁,让AI更好地符合我们每一个人利益的去发展,也需要在端和边上做更多的能力。
实时高清需要许多端上实时AI,在Low Level Vision and Audio这一层面,声网的SDK 4.1.x, 4.2.x版本已经可以支持1080P/4K视频的例如超分、虚拟背景、感知编码、降噪、去回声、质量感知等底层计算机视觉处理和计算机听觉处理能力。
在High Level Vision and Audio层面,声网已经部分实现对物体、声音、场景的理解和重构能力,包括面捕、动捕、情感计算,物体识别和场景重建等也取得一些进展,可以为在多种互动应用场景下为用户体验带来更好的体验。这些算法的一部分,我们已经集成到我们RTC SDK和即将发布的SDK里,不少客户已经用上了。这方面未来还有很多的工作需要做。
不久前,Facebook在他们的年度大会上介绍了一个智能眼镜(Meta Smart Glasses),据说其背后有GPT。对话助手这块可能是用LLAMA 2基础模型去支撑的,并且加了vision去帮助理解所看到的景物。我有一个体会,实时的AI就是VR必不可少的很重要的一部分,Real-time AI is VR,just more valuable。
RTE很美对吗?现在,我们有数十亿甚至更多台移动设备。未来如果能够在端上、在边缘提供实时AI智能和清晰画面和声音,这将是一件很美且值得追求的很有意义的事。