速途网3月15日讯(报道:乔志斌)今天凌晨,OpenAI 发布了多模态预训练大模型 GPT-4。GPT-4 实现了以下几个方面的飞跃式提升:强大的识图能力;文字输入限制提升至 2.5 万字;回答准确性显著提高;能够生成歌词、创意文本,实现风格变化。
GPT-4 是一个大型多模态模型,能接受图像和文本输入,再输出正确的文本回复。实验表明,GPT-4 在各种专业测试和学术基准上的表现与人类水平相当。OpenAI 花了 6 个月的时间使用对抗性测试程序和 ChatGPT 的经验教训对 GPT-4 进行迭代调整 ,从而在真实性、可控性等方面取得了有史以来最好的结果。
在过去的两年里,OpenAI 重建了整个深度学习堆栈,并与 Azure 一起为其工作负载从头开始设计了一台超级计算机。一年前,OpenAI 在训练 GPT-3.5 时第一次尝试运行了该超算系统,之后他们又陆续发现并修复了一些错误,改进了其理论基础。
OpenAI 今天还开源了 OpenAI Evals,这是其用于自动评估 AI 模型性能的框架。OpenAI 表示此举是为了让所有人都可以指出其模型中的缺点,以帮助 OpenAI 进一步改进模型。
有趣的是,GPT-3.5 和 GPT-4 之间的区别很微妙。当任务的复杂性达到足够的阈值时,差异就会出现 ——GPT-4 比 GPT-3.5 更可靠、更有创意,并且能够处理更细微的指令。
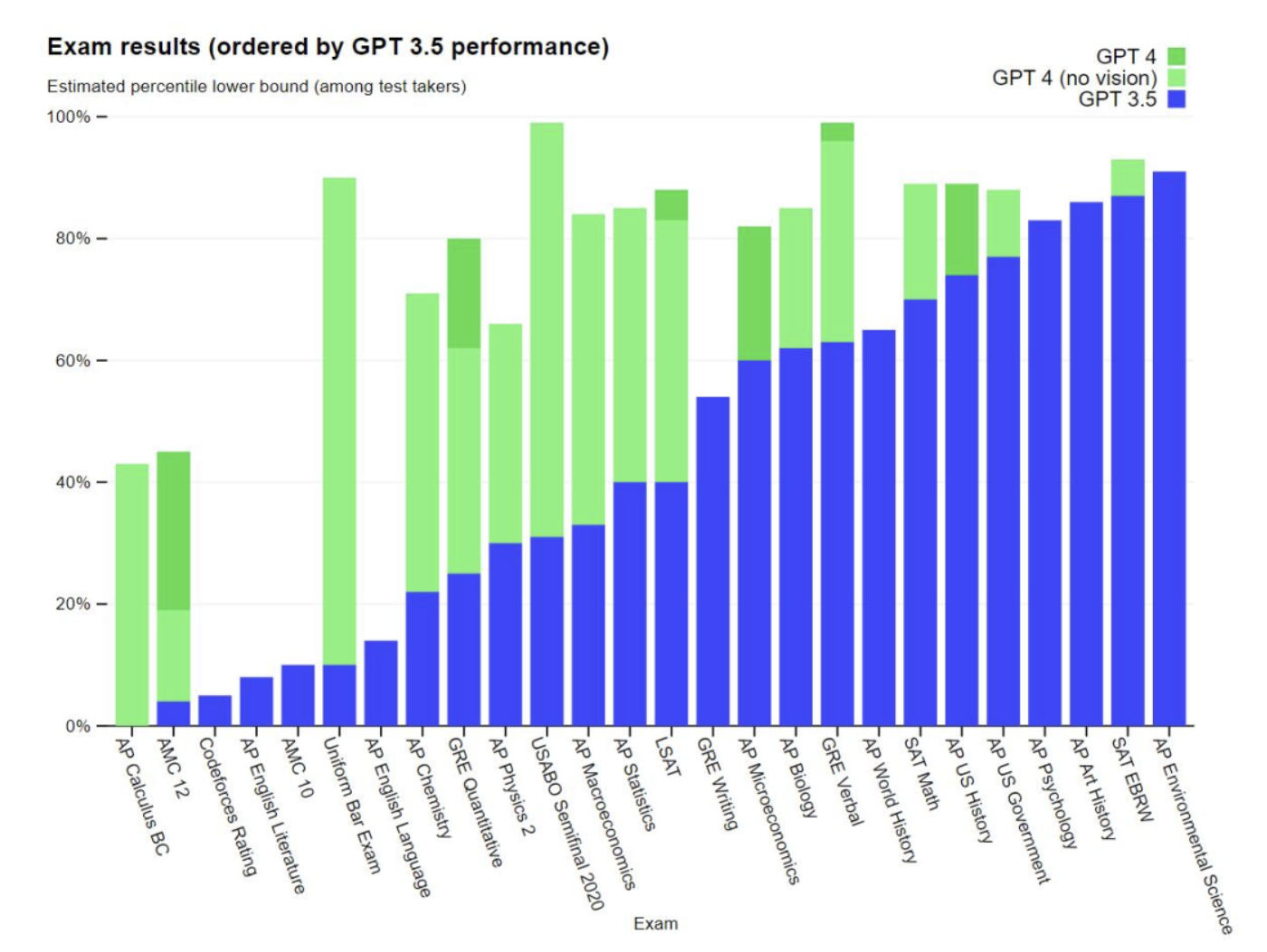
许多现有的机器学习基准测试都是用英语编写的。为了初步了解 GPT-4 在其他语言上的能力,研究团队使用 Azure Translate 将 MMLU 基准 —— 一套涵盖 57 个主题的 14000 个多项选择题 —— 翻译成多种语言。在测试的 26 种语言的 24 种中,GPT-4 优于 GPT-3.5 和其他大语言模型(Chinchilla、PaLM)的英语语言性能。
不仅如此,GPT-4还加入了识图的功能,允许用户指定任何视觉或语言任务。例如,给 GPT-4 一个长相奇怪的充电器的图片询问笑点在哪?


不过,OpenAI方面也指出,尽管功能已经非常强大, GPT-4 仍与早期的 GPT 模型具有相似的局限性,其中最重要的一点是它仍然不完全可靠。OpenAI 表示,GPT-4 仍然会产生幻觉、生成错误答案,并出现推理错误。
目前,使用语言模型应谨慎审查输出内容,必要时使用与特定用例的需求相匹配的确切协议(例如人工审查、附加上下文或完全避免使用) 。