1991年,比尔·恩门(Bill Inmon)出版了他的第一本关于数据仓库的书《Building the Data Warehouse》,标志着数据仓库概念的确立。
我们所常说的企业数据仓库Enterprise Data Warehouse (EDW) ,就是一个用于聚合不同来源的数据(比如事务系统、关系数据库和操作数据库),然后方便进行数据访问、分析和报告的系统(例如销售交易数据、移动应用数据和CRM数据),只要数据汇集到数仓中,整个企业都访问和使用,从而方便大家来全面的了解业务。我们的数据工程师和业务分析师可以将这些不同来源的相关数据应用于商业智能(BI)和人工智能(AI)等方面,以便带来更好的预测,并最终为我们作出更好的业务决策。
企业为什么需要实时数据仓库
传统意义上的数据仓库主要处理T+1数据,即今天产生的数据分析结果明天才能看到,T+1的概念来源于股票交易,是一种股票交易制度,即当日买进的股票要到下一个交易日才能卖出。
随着互联网以及很多行业线上业务的快速发展,让数据体量以前所未有的速度增长,数据时效性在企业运营中的重要性日益凸现,企业对海量数据的处理有了更高要求,如非结构化数据处理、快速批处理、实时数据处理、全量数据挖掘等。由于传统数据仓库侧重结构化数据,建模路径较长,面对大规模数据处理能力有限,企业急需提升大数据处理时效,以更经济的方式发掘数据价值。
数据的实时处理能力也成为企业提升竞争力的一大因素。
数据处理流程
在了解数仓如何实时处理之前,我们先来了解数据的分层。每个企业根据自己的业务需求可以分成不同的层次,但是最基础的分层思想,理论上数据分为三个层:贴源层(ODS)、数据仓库层(DW)、数据服务层(APP/DWA)。基于这个基础分层之上满足不同的业务需求。
ODS:Operation Data Store,也称为贴源层。数据仓库源头系统的数据表通常会原封不动的存储一份,这称为ODS层,是后续数据仓库加工数据的来源。
DW数据分层,由下到上一般分为DWD,DWB,DWS。
DWD:Data Warehouse Details 细节数据层,是业务层与数据仓库的隔离层。主要对ODS数据层做一些数据清洗(去除空值、脏数据、超过极限范)和规范化的操作。
DWB:Data Warehouse Base 数据基础层,存储的是客观数据,一般用作中间层,可以认为是大量指标的数据层。
DWS:Data Warehouse Service 数据服务层,基于DWB上的基础数据,主要是对用户行为进行轻度聚合,整合汇总成分析某一个主题域的服务数据层,一般是宽表。用于提供后续的业务查询,OLAP分析,数据分发等。
数据服务层/应用层(APP/DWA):该层主要是提供数据产品和数据分析使用的数据,我们通过说的报表数据,或者说那种大宽表,一般就放在这里。
实时数仓的常见方案
当前,数据仓库被分为离线数仓和实时数仓,离线数仓一般是传统的T+1型数据ETL方案,而实时数仓一般是分钟级甚至是秒级ETL方案。并且,离线数仓和实时数仓的底层架构也不一样,离线数仓一般采用传统大数据架构模式搭建,而实时数仓则采用Lambda、Kappa等架构搭建。
LAMBDA & KAPPA 实时架构
目前,实时处理有两种典型的架构:Lambda 和 Kappa 架构。出于历史原因,这两种架构的产生和发展都具有一定局限性。
Lambda架构:在离线大数据架构的基础上增加新链路用于实时数据处理,需要维护离线处理和实时处理两套代码;
Lambda 架构通过把数据分解为服务层(Serving Layer)、速度层(Speed Layer,亦即流处理层)、批处理层(Batch Layer)三层来解决不同数据集的数据需求。在批处理层主要对离线数据进行处理,将接入的数据进行预处理和存储,查询直接在预处理结果上进行,不需再进行完整的计算,最后以批视图的形式提供给业务应用。
在实际生产环境中的部署通常可以参见下图,一般要通过一系列不同的存储和计算引擎 (HBase、Druid、Hive、Presto、Redis 等) 复杂协同才能满足业务的实时需求,此外多个存储之间需要通过数据同步任务保持大致的同步。Lambda 架构在实际落地过程中极其复杂,使整个业务的开发耗费了大量的时间。
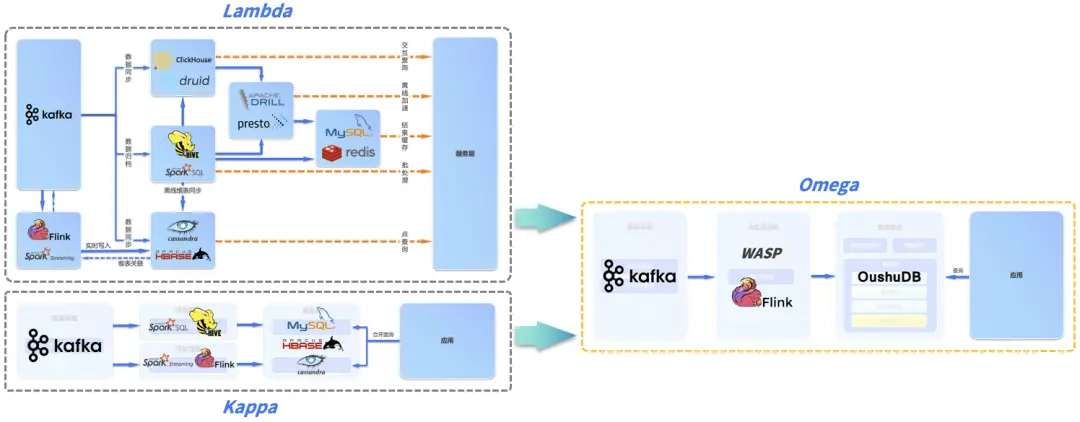
缺点:
(1) 由多个引擎和系统组合而成,批处理 (Batch)、流处理 (Streaming) 以及合并查询 (Merged Query) 的实现需要使用不同的开发语言,造成开发、维护和学习成本较高;(2) 数据在不同的视图 (View) 中存储多份,浪费存储空间,数据一致性的问题难以解决。
Kappa架构:希望做到批流合一,离线处理和实时处理整合成一套代码,减小运维成本。Kappa 架构在 Lambda 架构的基础上移除了批处理层,利用流计算的分布式特征,加大流数据的时间窗口,统一批处理和流处理,处理后的数据可以直接给到业务层使用。因为在 Kappa 架构下,作业处理的是所有历史数据和当前数据,其产生的结果我们称之为实时批视图(Realtime_Batch_View)。
Kappa 架构的流处理系统通常使用 Spark Streaming 或者 Flink 等实现,服务层通常使用MySQL 或 HBase 等实现。
Kappa 架构部署图
缺点:(1) 依赖 Kafka 等消息队列来保存所有历史,而Kafka 难以实现数据的更新和纠错,发生故障或者升级时需要重做所有历史,周期较长;(2) Kappa 依然是针对不可变更数据,无法实时汇集多个可变数据源形成的数据集快照,不适合即席查询。
因为上述的缺点,Kappa架构在现实中很少被应用。
湖仓一体能否解决实时问题?
时下热门的湖仓一体能否解决实时问题呢?湖仓一体有何标准?Gartner 认为湖仓一体是将数据湖的灵活性和数仓的易用性、规范性、高性能结合起来的融合架构,无数据孤岛。
作为数据湖和数据仓库的完美结合,新一代的湖仓一体架构重点关注和解决了近年来数字化转型带来的业务需求和技术难点,具体包括如下以下方面:
1.实时性成为了提升企业竞争力的核心手段。目前的湖、仓、或者湖仓分体都是基于 T+1 设计的,面对 T+0 的实时按需分析,用户的需求无法满足。
2.所有用户(BI 用户、数据科学家等)可以共享同一份数据,避免数据孤岛。
3.超高并发能力,支持数十万用户使用复杂分析查询并发访问同一份数据。
4.传统 Hadoop 在事务支持等方面的不足被大家诟病,在高速发展之后未能延续热度,持续引领数据管理,因此事务支持在湖仓一体架构中应得到改善和提升。
5.云原生数据库已经逐渐成熟,基于存算分离技术,可以给用户带来多种价值:降低技术门槛、减少维护成本、提升用户体验、节省资源费用,已成为了湖仓一体落地的重要法门。
6.为释放数据价值提升企业智能化水平,数据科学家等用户角色必须通过多种类型数据进行全域数据挖掘,包括但不限于历史的、实时的、在线的、离线的、内部的、外部的、结构化的、非结构化数据。
云原生数据仓库 + Omega实时架构 实现实时湖仓
云原生数据库实现完全的存算分离
云原生数据库如 OushuDB 和 Snowflake 突破了传统 MPP 和 Hadoop 的局限性,实现了存算完全分离,计算和存储可部署在不同物理集群,并通过虚拟计算集群技术实现了高并发,同时保障事务支持,成为湖仓一体实现的关键技术。以 OushuDB 为例,实现了存算分离的云原生架构,并通过虚拟计算集群技术在数十万节点的超大规模集群上实现了高并发,保障事务支持,提供实时能力,一份数据再无数据孤岛。
基于Omega实时框架的湖仓方案
我们前面提到,既然 Kappa 架构实际落地困难,Lambda 架构又很难保障数据的一致性,两个架构又都很难处理可变更数据(如关系数据库中不停变化的实时数据),那么自然需要一种新的架构满足企业实时分析的全部需求,这就是 Omega 全实时架构,Omega 架构由偶数科技根据其在各行业的实践提出,同时满足实时流处理、实时按需分析和离线分析。
Omega 架构由流数据处理系统和实时数仓构成。相比 Lambda 和 Kappa,Omega 架构新引入了实时数仓和快照视图 (Snapshot View) 的概念,快照视图是归集了可变更数据源和不可变更数据源后形成的 T+0 实时快照,可以理解为所有数据源在实时数仓中的镜像和历史,随着源库的变化实时变化。
因此,实时查询可以通过存储于实时数仓的快照视图得以实现。实时快照提供的场景可以分为两大类:一类是多个源库汇集后的跨库查询,比如一个保险用户的权益视图;另一类是任意时间粒度的分析查询,比如最近 5 分钟的交易量、最近 10 分钟的信用卡开卡量等等。
另外,任意时间点的历史数据都可以通过 T+0 快照得到(为了节省存储,T+0 快照可以拉链形式存储在实时数仓 ODS 中,所以快照视图可以理解为实时拉链),这样离线查询可以在实时数仓中完成,离线查询结果可以包含最新的实时数据,完全不再需要通过传统MPP+Hadoop湖仓分体组合来处理离线跑批及分析查询。
Omega 架构逻辑图
流处理系统既可以实现实时连续的流处理,也可以实现 Kappa 架构中的批流一体,但与Kappa 架构不同的是,OushuDB 实时数仓存储来自 Kafka 的全部历史数据(详见下图),而在 Kappa 架构中源端采集后通常存储在 Kafka 中。
Omega 架构部署图
因此,当需要流处理版本变更的时候,流处理引擎不再需要访问 Kafka,而是访问实时数仓 OushuDB 获得所有历史数据,规避了 Kafka 难以实现数据更新和纠错的问题,大幅提高效率。此外,整个服务层也可以在实时数仓中实现,而无需额外引入 MySQL、HBase 等组件,极大简化了数据架构,实现了湖仓市一体(数据湖、数仓、集市一体)。实现了全实时 Omega 架构的湖仓一体,我们也称之为实时湖仓一体。
Omega vs. Lambda vs. Kappa
结语:
面对复杂多变的新业务场景,随着数据技术不断成熟,新的实时技术栈会出现,数据技术也会经历分离与融合。目前,融合的趋势比较明显,如实时湖仓一体,将实时处理能力融入数据仓库中。不论企业如何选型实时数仓,数据平台技术栈的建设一般都应该遵循三条基本原则:
1.架构层面要保持灵活开放,支持多种技术兼容性并存。目前,企业已经部署了多个系统,有自己的一套架构体系,技术融合落地时需要最大化利用企业原有IT资产,保护客户投资。
2.有效利用资源,降本增效。原来传统的技术栈,所有资源参与计算,造成IT资源浪费。比如,云原生资源池化,可以实现资源隔离与动态管理,便于最大化利用资源。
3.满足更高的用户体验。从用户角度来看,在技术条件具备的前提下,比如高性能、高并发、实时性更强,便具备了更强的信息加工能力,能够在很短的时间内满足用户各种各样的数据服务需求,提升用户体验。
随着实时分析场景日益增多,实时数仓等具备实时处理能力的产品与解决方案将会得到更广泛的应用。