公司简介
杭州知衣科技有限公司是一家以人工智能技术为驱动的国家高新技术企业,致力于将数据化趋势发现、爆款挖掘和供应链组织能力标准化输出,打造智能化服装设计的供应链平台。知衣成立于2018年2月,同年获得千万美金A轮融资;2021年完成由高瓴创投、万物资本领投的2亿人民币B轮融资,同年入围“杭州市准独角兽企业榜单”。
知衣凭借图像识别、数据挖掘、智能推荐等核心技术能力,不断升级服务体系,自主研发了知衣、知款、美念等一系列服装行业数据智能SaaS产品,为服装企业和设计师提供流行趋势预测、设计赋能、款式智能推荐等核心功能,并通过SaaS入口向产业链下游拓展,提供一站式设计+柔性生产的供应链平台服务。目前已服务UR、唯品会、绫致、赫基、太平鸟、海澜之家、森马等数千家时尚品牌和平台。
方案架构
当前知衣在阿里云上的整体方案架构如下,大致分为产品层、服务层、数据层以及大数据平台。
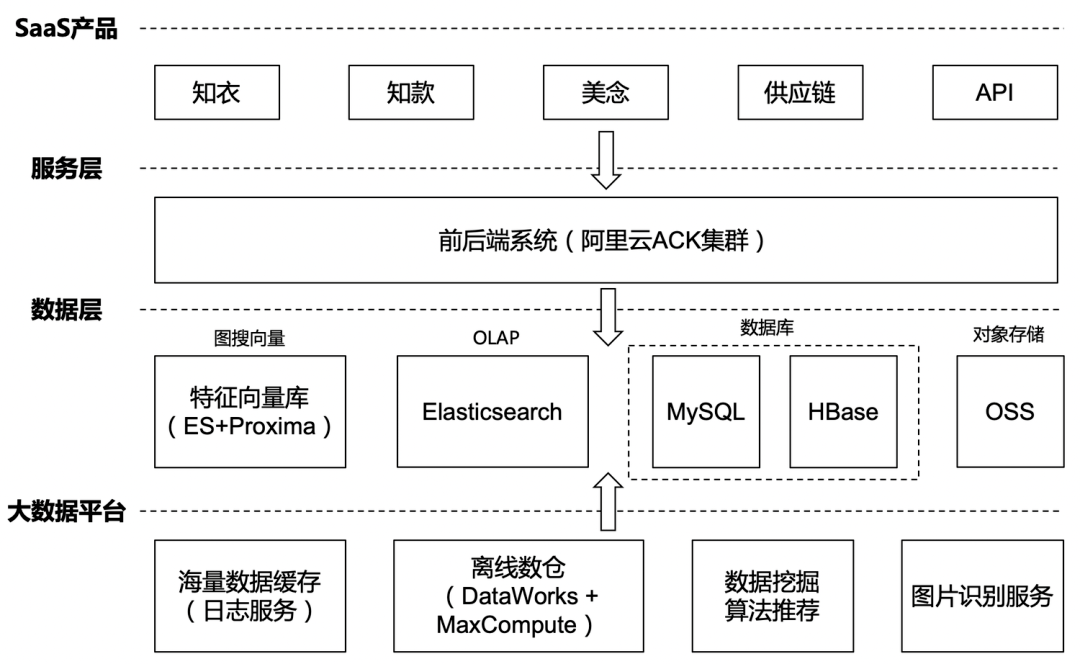
- 产品层:知衣目前有多款APP应用,如主打产品知衣、增强设计协作的美念等。除此之外,我们还提供定制化API向第三方开放数据接口服务和以图搜图的功能。从数字选款到大货成品交付的一站式服装供应链平台也是核心的能力输出。
- 服务层:相关产品的前后端系统都已经实现容器化,部署在阿里云的ACK容器服务集群
- 数据层:主要保存原始图片、业务系统产生的业务数据、以及OLAP数据分析服务
- 对象存储OSS:保存原始图片,构建服装行业十亿级别款式库
- 数据库MySQL:OLTP业务数据
- HBase:以KV格式访问的数据,如商品详细信息、离线计算榜单等数据
- 特征向量库:由图片识别抽取的向量再经过清洗后保存在阿里达摩院开发的Proxima向量检索引擎库
- ElasticSearch:用于点查及中小规模数据的指标统计计算。设计元素标签超过1000个,标签维度主要有品类、面料、纹理、工艺、辅料、风格、廓形、领型、颜色等
- 大数据平台
- 日志服务SLS:用于缓存经过图片识别后的海量向量数据。SLS还有一个基于SQL查询的告警能力,就是若向量数据没有进来会触发告警,这对于业务及时发现问题非常有用。
- 离线数仓(DataWorks + MaxCompute):通过DataWorks集成缓存了图片特征向量的日志服务作为数据源,然后创建数据开发任务对原始特征向量进行清洗(比如去重等)保存在MaxCompute,再通过DataWorks将MaxCompute清洗后的向量数据直接写入ElasticSearch的Proxima
- 数据挖掘 & 算法推荐:部署在ACK里的一些Python任务,主要做推荐相关的内容,比如用户特征Embedding计算、基于用户行为的款式图片的推荐、相似性博主的推荐等
- 图片识别服务:目前图片识别服务主要还是部署在IDC机房,5~6台GPU服务器对图片进行批量识别
大数据方案演进
知衣的大数据方案也是经过不同的阶段不断的演进,满足我们在成本、效率和技术方面的追求,本质上还是服务于业务需求。
阶段一:IDC自建CDH集群
我们的业务系统一开始就部署在阿里云,同时在IDC机房部署了10台服务器搭建CDH集群,构建Hive数仓。计算过程是先将云上生产环境数据同步到CDH,在CDH集群进行计算后将计算结果再回传到阿里云上提供数据服务。
自建CDH集群虽然节省了计算费用,但是也带来不少问题。最主要的就是运维比较复杂,需要专业的人员进行集群的运维管理。出现问题也是在网上到处搜索排查原因,效率比较低。
阶段二:DataWorks + MaxCompute替换CDH集群
为了降低运维复杂度,我们将计算任务迁移到MaxCompute,直接基于DataWorks做任务编排调度。
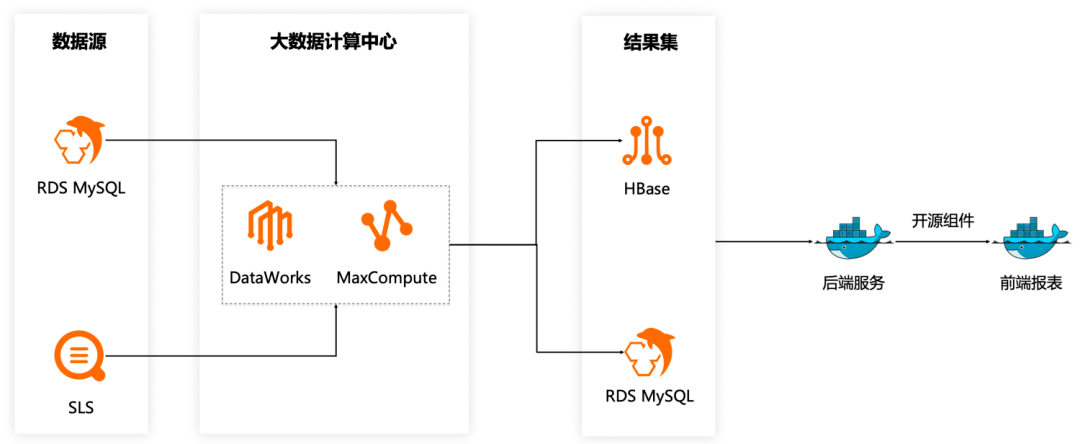
阶段三:ElasticSearch构建即席查询
知款聚焦于快速发现时尚趋势灵感,集成了社交平台、品牌秀场、零售及批发市场、淘系电商、时尚街拍五大图源,海量的设计灵感参考,帮助服装品牌及设计师快速准确地预判时尚风向,掌握市场动态。其中趋势分析板块就需要对某个季度下各种组合条件下的设计要素标签进行统计分析,并输出上升、下降以及饼图等指标。这也是我们数据量最大的查询场景,扫描分析的数据量量级会接近百万。
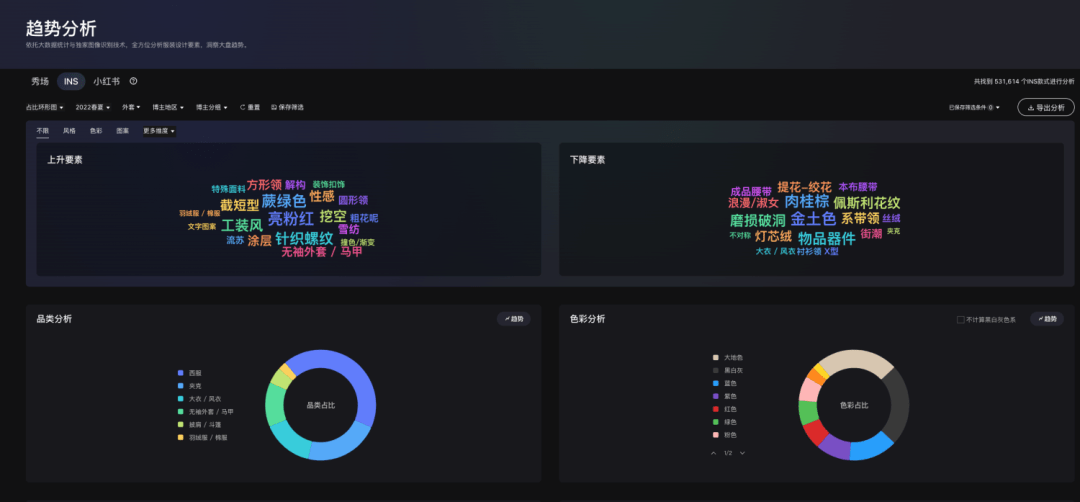
阿里云托管版ElasticSearch相比较开源版本最大优点就是开箱即用免运维,特别的就是支持达摩院的Proxima向量检索引擎,非常适合我们业务的多维查询和统计分析场景。后面会在图片识别展开讲述Proxima向量引擎。
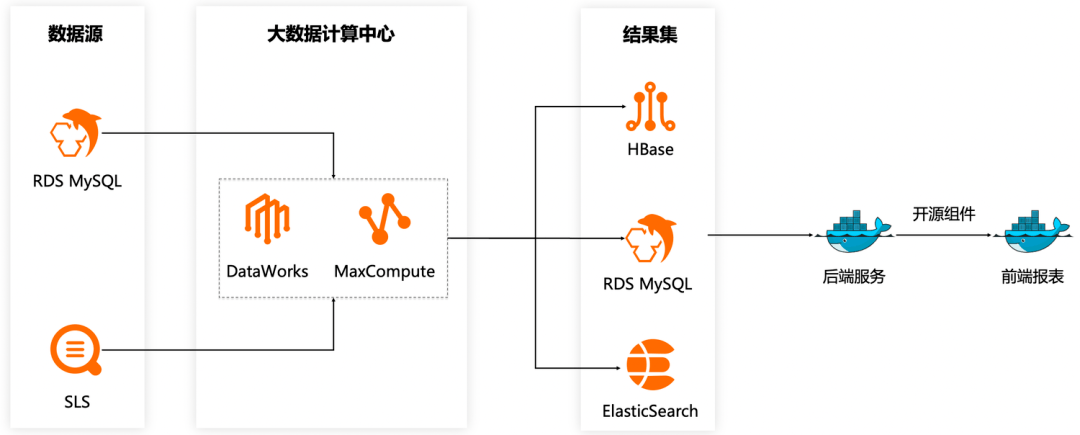
图片识别
我们的核心功能场景是以图搜图,前提是需要对海量的图片库数据进行识别。我们以离线的方式对图片库的所有图片进行机器学习分析,将每一幅图抽象成高维(256维)特征向量,然后将所有特征借助Proxima构建成高效的向量索引。
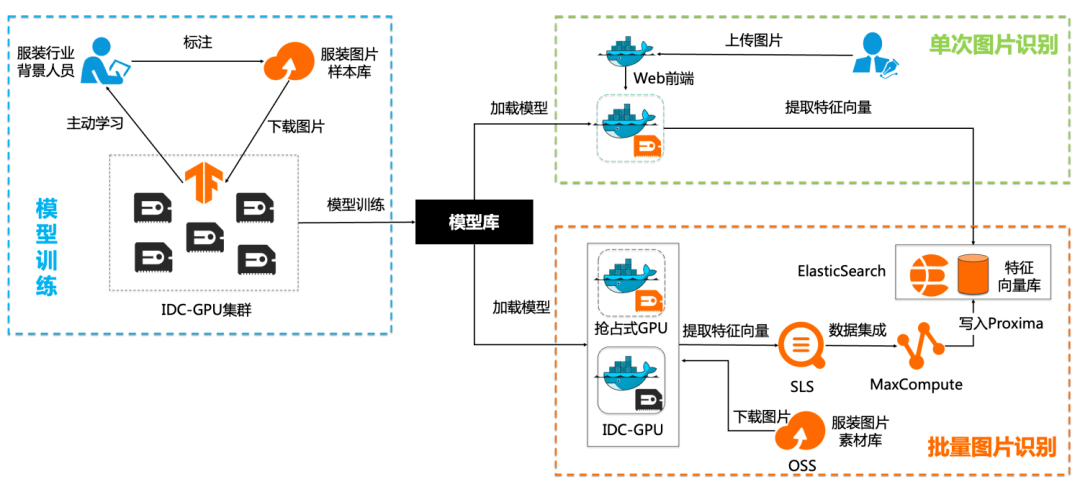
模型训练
图片识别之前需要训练模型。由专业的服务行业背景的人员对图片库进行标注,然后线下部署的GPU集群从阿里云对象存储OSS批量拉取已标注的图片进行训练。为了降低标注的成本,我们采用了主动学习(Active Learning)方法,即基于一部分已标注的图片由机器学习训练出一个模型,然后对未标注的图片进行预测,让人工对预测结果再次进行确认和审核,再将标注的数据使用监督学习模型继续进行模型训练,逐步提升模型效果。
批量图片识别
模型生成以后打包到Docker镜像,然后在GPU节点上运行容器服务就可以对海量的服装图片进行识别,提取出高维的特征向量。因为提取的特征向量数据量很大且需要进行清洗,我们选择将特征向量先缓存在阿里云日志服务SLS,然后通过DataWorks编排的数据开发任务同步SLS的特征向量并进行包含去重在内的清洗操作,最后写入向量检索引擎Proxima。
因为一次批量识别图片的工作量很大,线下的GPU服务器计算性能有瓶颈,所以我们就借助云上弹性的GPU资源做计算资源的补充。线下GPU和云上GPU组成一个计算资源池,共同消费同一批需要进行图片识别的计算任务,效率大大提升。云上我们购买的是GPU抢占式实例,一般是按量价格的2~3折,可以进一步降低成本。
单次图片识别
我们以在线serving的模式在web前端提供单次单张图片识别功能,比如用户上传一张图片,通过模型的推理输出如下结果。

以图搜图
构建好服装图片的特征向量库,我们就可以实现以图搜图的功能。当用户上传一张新图片的时候,我们用之前的机器学习方法对其进行分析并产出一个表征向量,然后用这个向量在之前构建的向量索引中查找出最相似的结果,这样就完成了一次以图片内容为基础的图像检索。选择合适的向量检索引擎非常重要。

Faiss
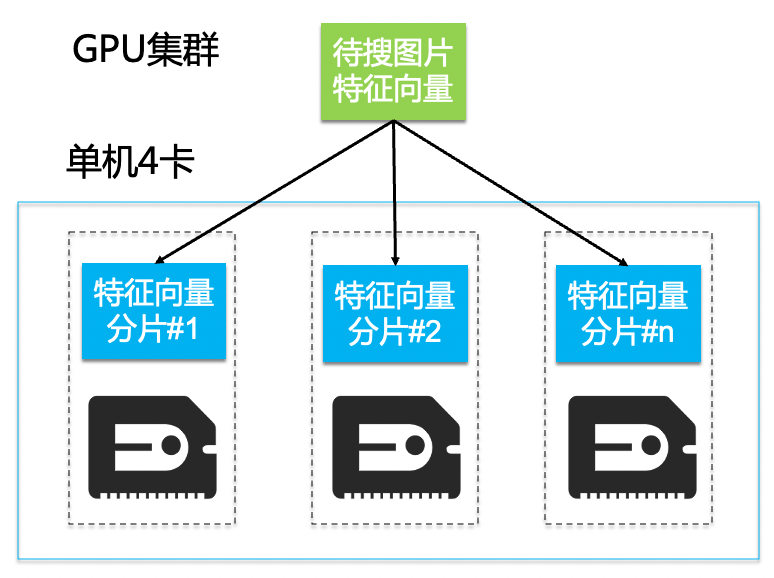
Faiss (Facebook AI Similarity Search) 是Facebook AI 团队开源的向量检索库引擎。初期我们也是选择Faiss部署分布式服务,在多台GPU服务器上部署特征向量搜索匹配服务,将搜索请求分发到每台GPU子服务进行处理,然后将TOP N的相似结果数据汇总返回给调用方。
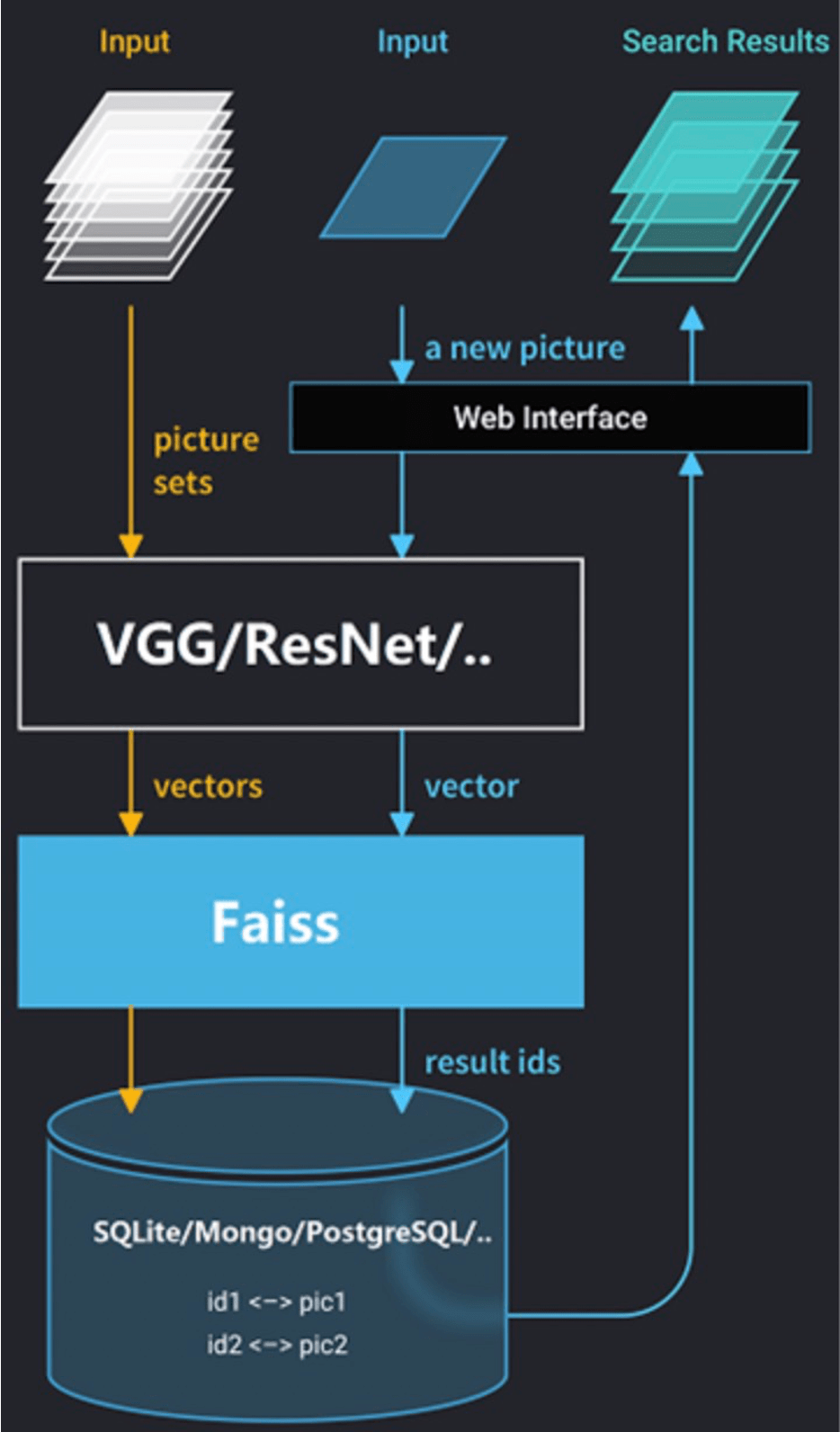
在使用Faiss的过程中,我们也遇到了实际的困难。当然这并不是Faiss本身的问题,而是需要投入更多人力开发运维分布式系统才能匹配业务需求。
- 稳定性较差:分布式GPU集群有5~6台,当某一台机器挂了会拉长整个接口响应时间,业务的表现就是搜图服务等很久才有结果返回。
- GPU资源不足:我们采用的是最基础的暴力匹配算法,2亿个256维特征向量需要全部加载到显存,对线下GPU资源压力很大。
- 运维成本高:特征库分片完全手动运维,管理比较繁琐。数据分片分布式部署在多个GPU节点,增量分片数据超过GPU显存,需要手动切片到新的GPU节点。
- 带宽争抢:图片识别服务和以图搜图服务都部署在线下机房,共享300Mb机房到阿里云的专线带宽,批量图片识别服务占用大带宽场景下会直接导致人机交互的图搜响应时间延长。
- 特定场景下召回结果集不足:因为特征库比较大,我们人工将特征库拆成20个分片部署在多台GPU服务器上,但由于Faiss限制每个分片只能返回1024召回结果集,不满足某些场景的业务需求。
Proxima
Proxima是阿里达摩院自研的向量检索引擎(https://developer.aliyun.com/article/782391),实现了对大数据的高性能相似性搜索,也集成在我们之前在用的阿里云托管版的ElasticSearch。功能和性能上与Faiss相比各有千秋,主要是针对Faiss使用上的困难,ElasticSearch + Proxima帮助我们解决了。
- 稳定性高:开箱即用的产品服务SLA由阿里云保障,多节点部署的高可用架构。到目前为止,极少碰到接口超时问题
- 算法优化:基于图的HNSW算法不需要GPU,且与Proxima集成做了工程优化,性能有很大的提升(1000万条数据召回只需要5毫秒)。目前业务发展特征向量已经增长到3亿。
- 运维成本低:分片基于ES引擎,数据量大的情况下直接扩容ElasticSearch计算节点就可以
- 无带宽争抢:以图搜图的服务直接部署在云上,不占用专线带宽,图搜场景下没有再出现超时查询告警
- 召回结果集满足业务需求:Proxima也是基于segment分片取Top N相似,聚合后再根据标签进行过滤。因为segment较多,能搜索到的数据量就比原先多很多。
技术架构升级展望
OLAP分析场景优化迭代
随着数据量的不断增长以及业务需求的不断变化,OLAP分析场景越来越复杂,对算法和技术方案选型要求越来越高。举个业务场景的例子:
10万博主发布的图片数量有1亿多,用户可以对博主进行关注订阅,关注上限是2000个博主。用户关注的2000个博主对应的图片量级会在200万左右。需要对用户关注的图片进行实时多条件统计分析(每个用户关注博主不同)
以上例子在使用Elasticsearch实现查询的时候需要9秒,显然不满足业务需要。那有没有更好的方案呢?近期在调研完Clickhouse之后,对数据进行预处理产生大宽表再查询,查询时延已经降低到2秒以内,很好的满足了业务需求。阿里云Clickhouse开箱即用,降低业务试错成本,帮助我们快速响应业务需求。
规范数据建模和数据治理
目前DataWorks主要是用来做数据集成和任务调度,也有些少量的基于规则判断数据质量,团队内部的约定更多的是文档化的开发规范,缺乏一些有效工具的辅助。随着业务场景越来越复杂,集成的数据源越来越丰富,数据开发人员也越来越多,制定全部门统一的开发规范非常必要。DataWorks的数据建模通过工具和流程建立数据标准,可以实现结构化有序的统一管理。数据治理模块可以通过配置检查项检测不符合数据规范的开发流程,基于多项治理项的健康分度量项目健康度以及治理成效。目前我们正在结合自己的业务试用数据建模和数据治理,期待能帮助我们更好的管理数据,实现数据价值的最大化。
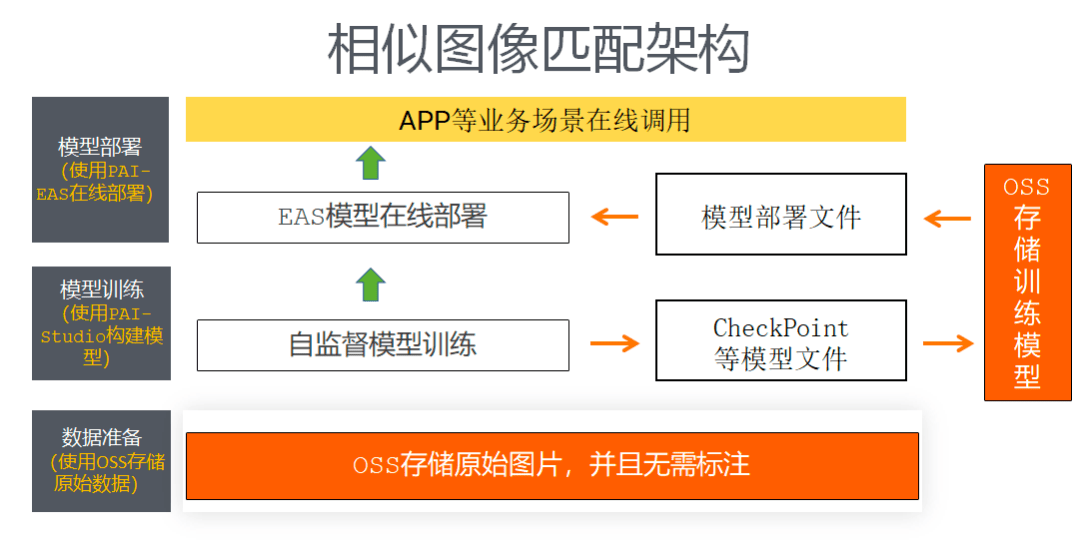
图搜方案进阶合作
在服装行业领域图片识别和以图搜图是我们的核心竞争力。阿里云机器学习PAI也提供了相似图匹配的图像检索解决方案(https://help.aliyun.com/document_detail/313270.html)只需要配置原始图像数据,无需标注就可以在线构建模型,这点对我们来说比较有吸引力,后续可以考虑进行测试对比,展开在服装图片建模领域的合作。