速途网12月8日讯(报道:乔志斌)今日,鹏城实验室与百度联合召开发布会,正式发布双方共同研发的全球首个知识增强千亿大模型——鹏城-百度·文心(模型版本号:ERNIE 3.0 Titan)。该模型参数规模达到2600亿,是目前全球最大中文单体模型,在60多项任务上取得最好效果。同时,百度产业级知识增强大模型“文心”全景图首次亮相,从技术自主创新和加速产业应用两方面,推动中国AI发展更进一步。
现场,中国工程院院士、鹏城实验室主任高文,百度首席技术官、深度学习技术及应用国家工程实验室主任王海峰共同启动发布仪式。

高文院士在致辞中表示,“预训练模型对整个科学的发展、社会的发展、创新的发展都是非常重要的工具。运用这个工具,可以帮助做很多人工智能的赋能,不局限于某个领域,这对人工智能的发展都是一个福音。”
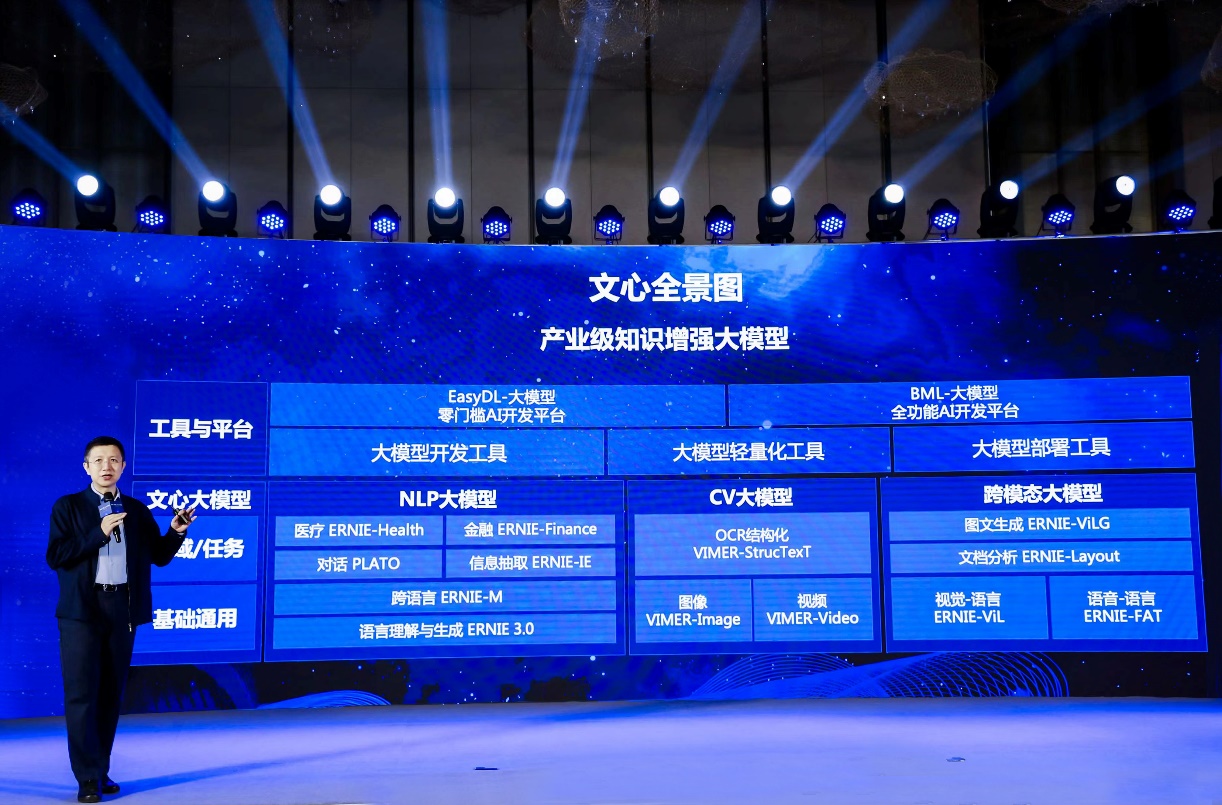
王海峰介绍,百度知识增强大模型从大规模知识和海量数据中融合学习,效率更高,效果更好,具有良好的可解释性。从2019年3月发布文心ERNIE 1.0,到最新的产业级知识增强大模型文心全景图,既包含基础通用的大模型,也包含面向重点领域、重点任务的大模型,以及丰富的工具与平台,有助于促进技术创新和产业发展。
此次重磅发布的鹏城-百度·文心是“全球首个知识增强千亿大模型”,在机器阅读理解、文本分类、语义相似度计算等60多项任务取得最好效果,并在30余项小样本和零样本任务上刷新基准。
鹏城-百度·文心成功发布的背后,得益于鹏城实验室的算力系统“鹏城云脑Ⅱ”和飞桨深度学习平台的强强联手,解决了超大模型训练的多个公认技术难题,使鹏城-百度·文心训练效率大幅提升,模型效果更优。“鹏城云脑Ⅱ”是国产自主的首个E级AI算力平台,曾在多个国际性能测试上获得冠军。飞桨是我国首个自主研发的深度学习开源开放平台,研制了端到端自适应分布式训练框架,实现多硬件支持,并行效率高达90%,有效支持鹏城-百度·文心千亿大模型高效、稳定地训练。
为解决大模型应用落地难题,百度团队首创大模型在线蒸馏技术,模型参数压缩率可达99.98%。压缩版模型仅保留0.02%参数规模就能与原有模型效果相当,为产业大规模应用打开新窗口。
为促进产学研协“多轮驱动”,鹏城实验室与百度成立了鹏城-百度自然语言处理联合实验室,并以此为依托,资源共享、优势互补,在自然语言处理前沿研究和创新应用方面协同攻关,助力打造国家战略科技力量。本次联合发布的鹏城-百度·文心将进一步解决 AI 技术在产业应用中缺乏领域和场景化数据等关键难题。本着“开源开放”的理念,该模型代码近期会在OpenI启智社区开源,依托鹏城云脑Ⅱ对外开放,积极联合“产学研协”各方,充分挖掘AI大模型的赋能能力,助力科技创新,推动产业发展。
目前,百度文心通过百度飞桨平台陆续对外开源开放,并已大规模应用于百度搜索、信息流、智能音箱等互联网产品,同时通过百度智能云赋能工业、能源、金融、通信、媒体、教育等各行各业。在金融领域,基于百度文心实现了合同智能解析,能够在1分钟内完成对相关合同条款文本的解析识别,速度是之前的几十倍,大大提升了工作效率。百度智能云的智能客服也基于百度文心提升了服务的精准性,目前已经在中国联通、浦发银行等企业应用,拓展到全国各地。
从AI核心技术到AI基础平台,从技术创新到实践落地再到开放生态,多年来,以百度为代表的中国AI企业坚持自主创新、开源开放,加强产学研协合作,不断降低AI技术开发和应用的门槛,为各行各业提供高质量发展新动能。