近日,自然语言处理(NLP)领域的顶级会议ACL 2021(Annual Meeting of the Association for Computational Linguistics)和人工智能领域的顶级会议IJCAI 2021(International Joint Conference on Artificial Intelligence)相继揭晓论文录用结果,专注医疗人工智能与大数据技术研究的腾讯天衍实验室共有3篇长文被ACL 2021主会录用,1篇长文被Findings of ACL录用,1篇长文被IJCAI 2021录用,论文内容涵盖信息抽取、问题生成、文档检索以及知识图谱对齐等经典NLP研究方向。此外,在近期公布的数据挖掘领域国际会议PAKDD获奖名单中,腾讯天衍实验室在疾病预测领域的最新研究进展也荣获了最佳学生论文奖项。
随着AI技术与医疗行业走向深度融合,应用AI助推医疗智慧化、数字化升级已经成为未来发展方向之一。在本次获录的多篇论文中,腾讯天衍实验室基于医学AI临床应用中的多种场景,针对多种机器学习方法展开了创新性研究,研发突破多项行业技术应用难点,有望充分释放AI在医疗场景运用中的潜力,加速助推AI在医疗健康领域的实践进程。

ACL是计算语言学和自然语言处理领域影响力最大、最具活力的国际学术会议之一,由计算语言学协会主办,每年都会有众多顶级学术机构和科技企业如斯坦福大学、谷歌等,在会议上提交在自然语言处理、人工智能、机器学习方面的最新研究成果。2021年ACL共收到3350篇长文投稿,主会录用率21.3%。IJCAI则是国际人工智能联合会议,也是人工智能研究人员和实践者的顶级国际聚会,在人工智能领域备受学界关注,2021年共收到4204篇有效投稿,最终录用率仅为13.9%。
读懂医疗文档中的复杂关联
在医疗查询领域,天衍实验室提供了多种医疗文档检索功能,如相似病例检索,基于医疗文档的检索与问答等。由于检索速度和内存占用的需求,文档哈希在现今的大规模信息检索系统中扮演着越来越重要的角色。大量工作表明,医疗文本之间的语义以及邻居信息在该文本的编码和表达过程中往往扮演着更重要的角色,也对生产高质量哈希码起着关键作用。为了将两种信息良好地融合,在论文中,天衍实验室将邻居信息建模在基于图诱导的高斯分布中,并通过图驱动生成模型将语义和邻居信息融合。
为了进一步处理文档直接复杂的关联关系,天衍实验室进一步提出基于树结构的近似方法来加速训练。通过该近似方法,证明了训练目标可以被分解为多个单个文档或文档对,从而提高模型的训练效率。通过结合文本本身的语义信息及文档之间的相关性,该算法能很好地将文档相似性映射到哈希码中,从而大大提高了文档检索的速度。

在智能问答场景下,天衍实验室也开发设计了多种不同的问答助手,例如在医保政策问答助手,嵌入各地医保相关服务公众号,协助回答用户医保政策相关的各类问题。然而,由于医疗场景的特殊性,天衍实验室的研究员们发现先要获取到大量高质量的问答语料是很困难的,因此在论文中,研究人员提出一种难度可控的多跳问题生成技术,旨在生成那些需要对文本中多处内容、进行多层推理才能作答的困难问题。
具体来说,对于一篇给定的文本c和指定的问题推理层级d,该技术将先对其内容进行构图,然后从中抽取一条推理链,以此生成相关问题。先由一个简单问题生成器QGInitial生成一个初始问题,再使用另一个问题改写模型QGRewrite将其改写为一个更困难的问题。QGRewrite共将重复使用d-1次,从而将问题逐步改写为包含d层推理的复杂问题。在未来,该问题生成技术可用于为医保政策、医疗文献生成配套试题,测试相关人员的掌握程度。

除此之外,在医疗场景中,从医学相关文本中提取关键信息也一直是NLP在业务中落地的一个核心切入点。例如在篇章级别的药品说明书中抽取(药品,适应症,疾病)等各种关系三元组构成药品知识库以支持处方合理性审核,用药推荐等多个业务场景。但在实际算法设计过程中,研究人员发现由于医疗知识的复杂性,不同实体类别之间两两组合可以构成多种关系,而冗余的关系类别会极大的影响模型效率和表现,所以天衍实验室提出一个全新的关系抽取框架,将其拆分为三个子任务:关系类别预测,实体抽取以及头尾实体配对。
首先,该模型通过关系类别预测模块从冗余的备选关系中选取最有可能的关系子集,然后以预测得到的关系类别作为序列标注的标签抽取相关实体,在此过程中,研究人员也利用序列标注技术的特点解决了头尾实体嵌套的问题,最后模型通过构建实体词之间的关联矩阵完成头尾实体之间的组合配对。一系列实验结果都证明该模型不仅提升了关系抽取的效率,也在NYT和WebNLG等多个关系抽取数据集上达到了SOTA效果。

破解医疗知识图谱对齐技术瓶颈
医疗知识图谱是医疗信息化中最重要的一项技术,也是实现智慧医疗的基石。在构建和更新医疗知识图谱时,知识图谱的对齐技术可以将多个不同来源的多个异构医疗知识图谱进行实体和本体两个层面的对齐,以构建知识覆盖度更广的医疗知识图谱。在天衍实验室的实际业务中,研究人员也是利用了知识图谱对齐技术将各个业务上的医疗垂域知识图谱进行对齐融合,形成了一整套大规模高置信的医疗知识图谱,作为驱动腾讯智能医疗的重要根基。在这次放榜的两大会议中,天衍实验室也发表了两篇知识图谱对齐方向的最新研究成果。
现有的知识图谱对齐方法大体上可以分为基于推理的传统方法和基于神经网络的方法,两者有各自的优势但又存在着各自的问题:基于推理的传统方法无法有效利用知识图谱的图结构信息,而基于神经网络的方法无法利用适当的推理来减少错误对齐。因此,天衍实验室提出了一种迭代框架(PRASE),将两种方法有效地融合,来达成相互增强的目的。天衍实验室的PRASE框架可以兼容传统方法PARIS和多种神经网络方法。在多个公开数据集和一个工业数据集(医疗知识图谱)上均表现出了PRASE的SOTA性能。

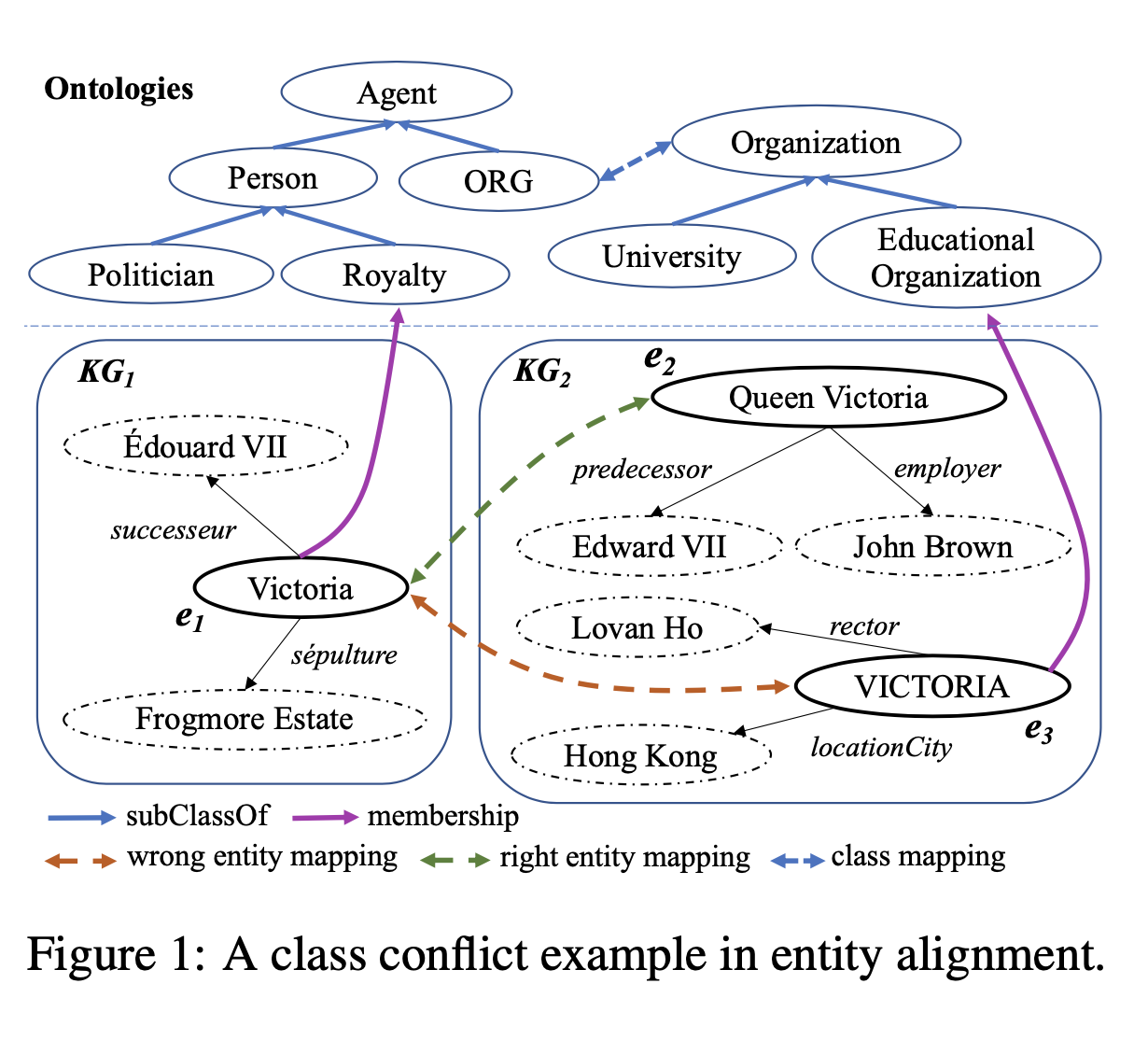
知识图谱表示学习常常用在知识图谱对齐任务上,但是目前的表示学习模型通常只会建模图结构信息、实体名称信息、实体属性信息,而没有考虑知识图谱的本体信息。本体定义了知识图谱的元信息以及实体的类别信息,在知识图谱及其应用中有重要作用。在论文中,天衍实验室提出了一种基于本体指导的知识图谱对齐模型(OntoEA),将知识图谱和本体层级信息共同进行建模,来发现并避免错误实体对齐中的类别冲突(class conflict)。天衍实验室提出的OntoEA模型在多个公开数据集和一个工业数据集(医疗知识图谱)上均超过了现有的知识图谱对齐模型,这也证明了引入本体信息的有效性。
突破AI临床辅诊“普适性”难题
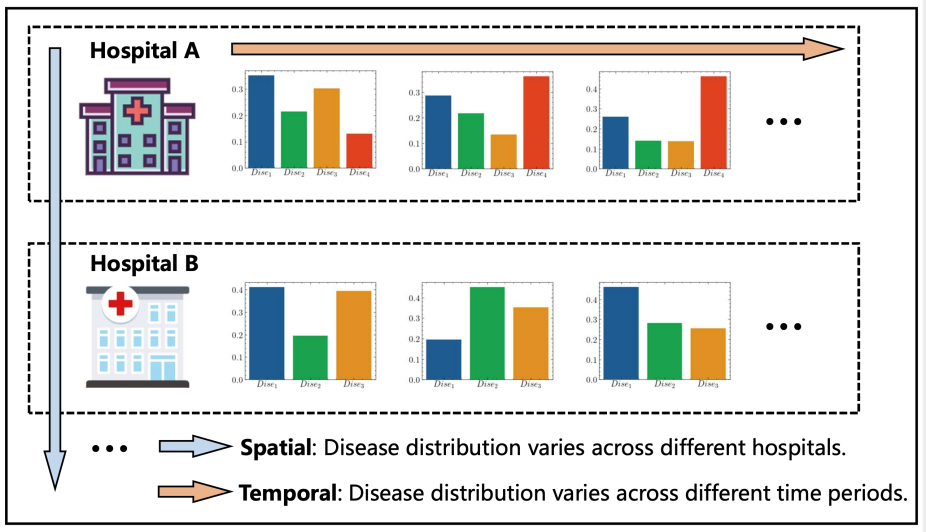
在实际业务场景中,辅诊系统需要落地到不同的医院,而不同医院的接诊病例、疾病体系存在较大的差异,研究人员不断接到新的医院数据,遇到新的疾病类别。随着数据量的增多,结合全量数据进行模型训练会耗费大量存储和计算资源。面对此问题,研究人员考虑将其建模为一个增量学习的过程,即以序列形式,训练多个机器学习模型的任务,保证模型对新旧类别的数据均具有良好的识别性能。
首先研究人员在模型中加入基于医疗实体抽取的预测通道,以文本中的医疗实体作为输入,该预测通道既增大了医疗实体在疾病预测模型中的作用也为疾病预测的结果提供了一定的可解释性。另外研究人员提出对于文本,实体两个预测通道的编码结果进行二次映射,构建一个基于医疗普适知识的特征空间,并不断复用到新的任务中,保证在新任务所学到的特征能够和之前任务所学到的特征进行一定程度的融合,以达到同一模型迅速复用于新医院新疾病体系且避免灾难性遗忘的目的。
本次天衍实验室多篇上会论文不仅在研发层面实现多项重磅技术突破,具有重要学术价值和临床应用价值,研究员们也将其技术输出到腾讯健康小程序、QQ浏览器、微信搜一搜等C端应用、以及AI基层司、智慧医保、公卫等B/G端应用,将创新科技落地到实际应用中,以进一步服务医生和患者,从社会实践层面发挥科技创新助力医疗行业智慧化发展的普世价值。
作为医疗AI 领域的创新力量,腾讯天衍实验室秉承“科技向善”核心理念,一直以来专注于医疗健康领域AI算法研究及落地,以实际场景为依托不断在NLP,知识图谱、大数据以及医疗影像等领域探索最前沿的技术,已成功支持了数百家医院的辅诊、导诊、疾病辅助诊断、智能用药等产品,助力医保、医院、疾控中心和其他医疗机构的智能化知识挖掘和管理难题,实现知识化转型。
ACL 2021主会录用论文3篇:

Findings of ACL录用1篇

IJCAI 2021录用1篇:

PAKDD 2021最佳学生论文1篇:
